
医疗数字化热门
 瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
 波士顿科学、美敦力百亿并购争相出手,这一赛道成必抢风口
波士顿科学、美敦力百亿并购争相出手,这一赛道成必抢风口
 元宇宙一股风,医疗AR又重燃
元宇宙一股风,医疗AR又重燃
 60年3次突破,下一代康复机器人该如何发展
60年3次突破,下一代康复机器人该如何发展
 百亿市场的国产化蛋糕
百亿市场的国产化蛋糕
 跨模态编码刺激(视觉-语言大脑编码)实现脑机接口
跨模态编码刺激(视觉-语言大脑编码)实现脑机接口

推荐资讯
让区块链变成人人可用的工具,上海原创Web3.0操作系统是如何诞生的
隐私之变|自我主张时代变革,从构建WEB3.0的ID体系开始
被投资圈盯上,风头超过元宇宙,Web3.0到底是啥?
Web3.0,勾勒下一代互联网模样
为什么说中国汽车产业已经真正“支棱”起来了
我在新能源汽车行业打工10年:从月薪2千涨至年薪40万,终于熬出头
 对话梅宏院士:数字化转型不是想不想,而是必须转
对话梅宏院士:数字化转型不是想不想,而是必须转
 王兴继续“电商零售梦”:告别社区团购 美团优选变身明日达超市
王兴继续“电商零售梦”:告别社区团购 美团优选变身明日达超市

跨模态编码刺激(视觉-语言大脑编码)实现脑机接口
 财经快报
|
2022/08/26 19:20:49
财经快报
|
2022/08/26 19:20:49
实现有效的脑-机接口需要理解人脑如何跨模态(如视觉、语言(或文本)等)编码刺激。大脑编码旨在构建fMRI大脑活动给定的刺激。目前有大量的神经编码模型用于研究大脑对单一模式刺激的编码:视觉(预训练的CNN)或文本(预训练的语言模型)。通过获得单独的视觉和文本表示模型,并使用简单的启发式进行后期融合。然而,以前的工作未能探索:(a)图像转换器模型对视觉刺激编码的有效性,以及(b)协同多模态模型对视觉和文本推理的有效性。在本研究中首次系统地研究和探讨了图像转换器(ViT,DEiT和BEiT)和多模态转换器(VisualBERT,LXMERT和CLIP)对大脑编码的有效性,并发现:VisualBERT是一种多模态转换器,其性能显著优于之前提出的单模态CNN、图像转换器以及其他之前提出的多模态模型,从而建立了新的研究状态。
脑成像数据集
以下数据集在文献中被广泛用于研究大脑编码:Vim-1、 Harry Potter 、BOLD5000、Algonauts和SS-fMRI。
Vim-1只有黑白图像,只与物体识别有关,并被BOLD5000所包含。SS-fMRI更小,与BOLD5000非常相似。Harry Potter数据集没有图像。fMRIs还没有为Algonauts数据集公开。因此,在这项工作中,对BOLD5000和Pereira数据集进行了实验。

图1:大脑编码方法。使用来自图像/多模态转换器(如ViT、Visual-BERT和LXMERT)的特征作为回归模型的输入,预测不同大脑区域的fMRI激活。通过计算2V2准确度和实际激活与预测激活之间的Pearson相关性来评估脑编码结果。在transformer层和脑区之间进行分层相关性分析。
从4个受试者中,3个受试者观看了5254幅自然图像(ImageNet:2051,COCO:2135,Scenes:1068),同时获得了fMRI。第4名受试者只观看了3108幅图像。附录表1中简要总结:了数据集的细节。数据涵盖了人类视觉皮层中的五个视觉区域,即早期视觉区(early visual area,EarlyVis);对象相关区域,如枕外侧复合体(LOC);以及场景相关区域,如枕区(OPA)、海马旁区(PPA)和脾后复合体(RSC)。每张图片也有相应的文本标签:ImageNet每张图片1000个可能的标签中有几个,COCO每张图片有5个标题,而Scenes每张图片250个可能的类别中有一个。专注于对应于4个脑网络的9个脑区域:默认模式网络(DMN)(与语义处理的功能相关)、语言网络(与语言处理、理解、词义和句子理解相关)、任务积极网络(与注意力、显著信息相关)和视觉网络(与视觉对象、物体的处理相关,物体识别)。在附录表2中简要总结:了数据集的细节和每个区域对应的体素数量。
任务描述
对于这两个数据集,在使用各种模型获得的刺激表征上使用脊回归训练fMRI编码模型,如图1所示。每个fMRI编码器模型的主要目标是预测给定刺激的每个大脑区域的fMRI体素值。在所有情况下,为每个受试者单独训练一个模型。不同的大脑区域参与处理涉及物体和场景的刺激。同样,一些区域专门理解视觉输入,而另一些区域更好地解释语言刺激。为了理解模型在这些认知方面(物体vs.场景,语言vs.视觉)的泛化性,进行了以下实验。每当在同一个数据集上训练和测试时,都会遵循K折(K=10)交叉验证。所有来自K-1折叠的数据样本都被用于训练,模型在左侧折叠的样本上进行测试。全数据集fMRI编码:对于每个数据集,进行 K-fold (K=10)交叉验证。
交叉验证的fMRI编码在BOLD5000数据集中,有三个子数据集:COCO、ImageNet和Scenes。Ima geNet图像主要包含对象。场景图像是关于自然场景的,而COCO图像既涉及物体,也涉及场景。为了评估模型在物体与场景理解上的泛化性,还对训练图像进行了交叉验证实验。
训练图像属于一个子数据集,而测试图像属于另一个子数据集。因此,对于每个受试者,进行(1)3个相同子数据集的训练-测试实验和(2)6个跨子数据集的训练-测试实验。因此,对每个主题进行两种不同设置的实验:(抽象训练,具体测试)和(具体训练,抽象测试)。
方法
本研究中训练了一个基于 脊回归 的编码模型,以预测每个脑区与刺激表征相关的fMRI脑活动。使用单独的脊回归模型预测每个体素值。输入刺激表示可以使用以下任何模型获得 (i)预训练的CNN,(ii)预训练的文本转换器(ii)图像转换器,(iv)后期融合模型,或(v)多模态转换器 。
预训练CNN: 从不同的预训练 CNN模型中提取分层特征,如VG-GNet19(Max- Pooll,MaxPool2,MaxPool3,MaxPool4,Max-Pool5,FC6,FC7,FC8),ResNet50(Block1,Block2,Block3,Block4,FC),In-ceptionV2ResNet(con2d5,con2d50,con2d100,con2d150,con2d200,con2d 7b),和EfficientNetB5(con2d2,con2d8,con2d16,con2d24,FC),并使用它们预测fMRI脑活动。在这里,在每一层上使用自适应平均池化来获得每一幅图像的特征表示。
预训练文本转换器: RoBERTa建立在BERT的语言屏蔽策略上,并在流行的GLUENLP基准上被证明优于其他几个文本模型。使用RoBERTa的平均池化表示来编码文本刺激。
图像转换器: 使用了三种图像转换器:视觉转换器(ViT)、数据高效图像转换器(DEIT)和来自图像转换器的双向编码器表示(BEiT)。给定一幅图像,图像转换器输出两种表示:池和块。对这两种表示进行了实验。
后期融合模型 :在这些模型中,刺激表示是由从预训练的CNN中获得的图像刺激编码和从预训练的文本转换器中获得的文本刺激编码的串联得到的。因此,对这些后期融合模型进行了实验:VGGNet19+RoBERTa,ResNet50+RoBER Ta,InceptionV2ResNet+RoBERTa 和Efficient-NetB5+RoBERTa。这些模型没有融合真实的信息,只是跨模态进行了级联。
多模态转换器: 对这些多模态转换器模型进行了实验:对比语言图像预训练(CLIP)、从转换器中学习跨模态编码器表示(LXMERT)和Visualalbert。这些转换器将图像和文本刺激都作为输入,并输出视觉-语言联合表示。具体而言,这些模型的图像输入包括区域建议以及从Faster R-CNN提取的边界框回归特征作为输入特征,如图1所示。这些模型在使用共同注意的不同处理水平上合并了跨模态的信息融合,因此是预计将产生高质量的视觉语言表示。
超参数设置: 使用了sklearm的默认参数的脊回归、K-fold(K=10)交叉验证、随机平均梯度下降优化器、转换器模型的Huggin gface、MSE损失函数和L2衰减。使用词块标记器作为语言转换器的输入,并使用Faster-RCNN提取区域建议。所有实验都是在一台带有1个NVIDIA GEFORCE-GTX GPU和16GB GPU RAM的机器上进行的。
实验
评价指标
使用大脑编码评估指标2V2 Accuracy评估该模型。给定一个受试者和一个大脑区域,设N为样本数量。设表示第i个样本的实际和预测体素值向量,其中V是该区域的体素数。 2V2 Accuracy 的计算如下。
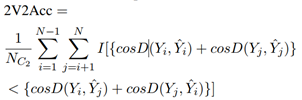
其中cosD为余弦距离函数。I[c]是一个指示函数,使I[c]=1如果c为真,否则为0。2V2 Accuracy越高越好。
结果
这里给出了用不同方法训练的模型的2V2准确度和Pearson相关性结果。分别在图2和图4中的BOLD5000和Pereira两个数据集上输入表示(从每个预训练的CNN模型的最佳表现层和transformer模型的最后输出层提取的特征)。并对附录图8和图9中CNN模型和Transformer模型的最后一层使用许多中间层激活(不仅仅是最好的)的结果进行了比较。此外,还比较了附录图10和图11中Transformer模型使用所有中间层激活的结果。
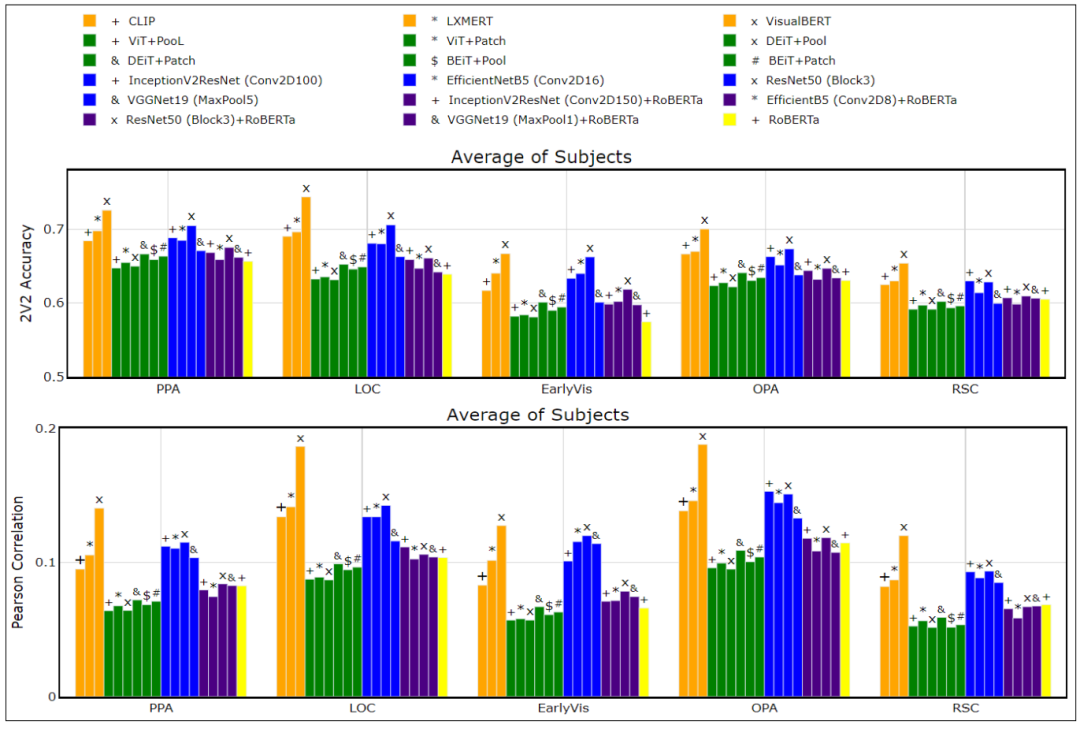
图2:BOLD5000结果:使用各种模型在不同脑区预测和真实反应之间的2V2(上图)和Pearson相关系数(下图)。对所有参与者的结果进行了平均。VisualBERT表现最好。
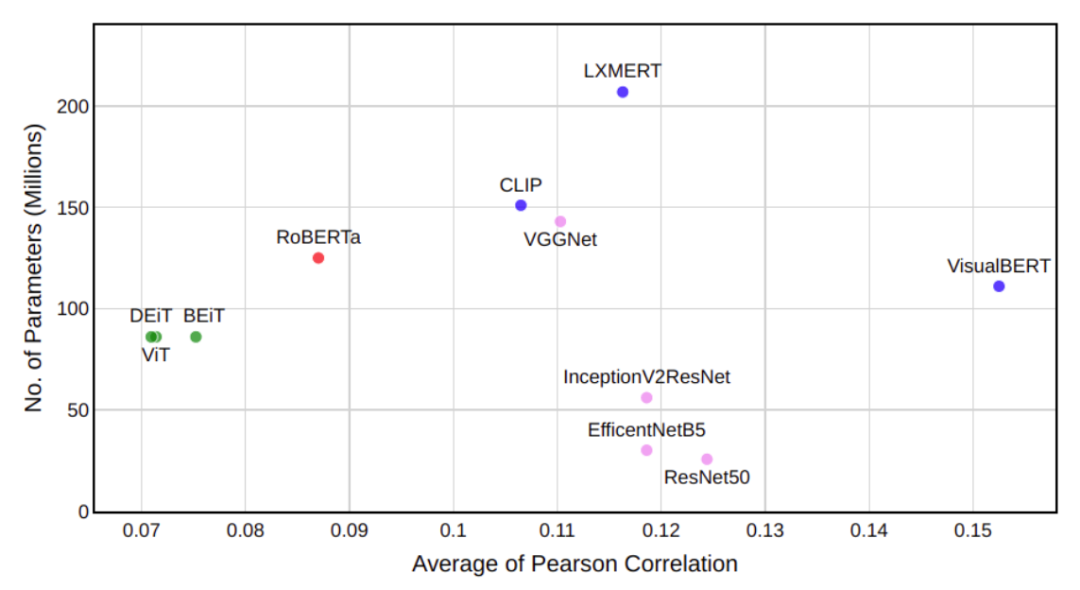
图3:BOLD5000: #参数vs Pearson Corr均值
BOLD5000: 从图2中进行了以下观察:
(1)在2V2准确度和Pearson相关性方面,VisualBERT在所有模型中都更好。
(2)其他多模态转换器,如LXMERT和CLIP的表现与预训练的CNN一样好。然而,图像转换器的表现比预训练的CNN差,后期融合模型和RoBERTa表现最差。
(3)后期视觉区域,如OPA(场景相关)和LOC(物体相关),与多模态转换器显示出更高的Pearson相关性,这与视觉处理层次是内联的。总的来说,多模态转换器与所有视觉脑区ROI的相关性更高,这表明联合编码视觉和语言信息的能力。
(4)与合并表示相比,图像转换器的块表示具有更高的2V2准确度和Pearson相关性。
(5)在单模模型中,InceptionV2ResNet和ResNet-50均有较好的表现。
为了估计性能差异的统计学意义,对所有受试者在5个脑感兴趣区进行了双尾t检验。研究发现,VisualBERT在除EarlyVis外的所有感兴趣区均优于LXMERT(次优多模态转换器)和InceptionV2ResNet(最佳预训练CNN)。最后,在所有感兴趣点上,InceptionV2ResNet均显著优于BEiT(best image Transformer)(附录表3中提到了详细的p值)。

图4:Pereira结果:使用各种模型在不同大脑区域预测和真实反应之间的2V2(上图)和Pearson相关系数(下图)。所有参与者的结果是平均的。VisualBERT表现最好。
Pereira: 从图4中进行了如下观察:
(1)与BOLD5000类似,VisualBERT和LXMERT等多模态转换器的性能更好。
(2)横向视觉区域如Vision Object、Vision Body、Vision Face和视觉区域与多模态转换器表现出更高的相关性。与所有视觉大脑区域,语言区域,DMN和TP的高相关性与多模态变形器,表明对齐的视觉语言理解有帮助。
为了估计性能差异的统计显著性,对所有受试者在9个脑感兴趣区进行了双尾t检验。发现VisualBERT在除Vi-sion Body外的所有感兴趣区均显著优于LXMERT(次优多模态转换器)。此外,VisualBERT在除Vision Object和Vi-sion Scene外的所有roi上均显著优于ResNet(最佳预训练CNN)。最后,ResNet在所有roi上都显著优于ViT(best image Transformer)(附录表4中提到了详细的p值)。
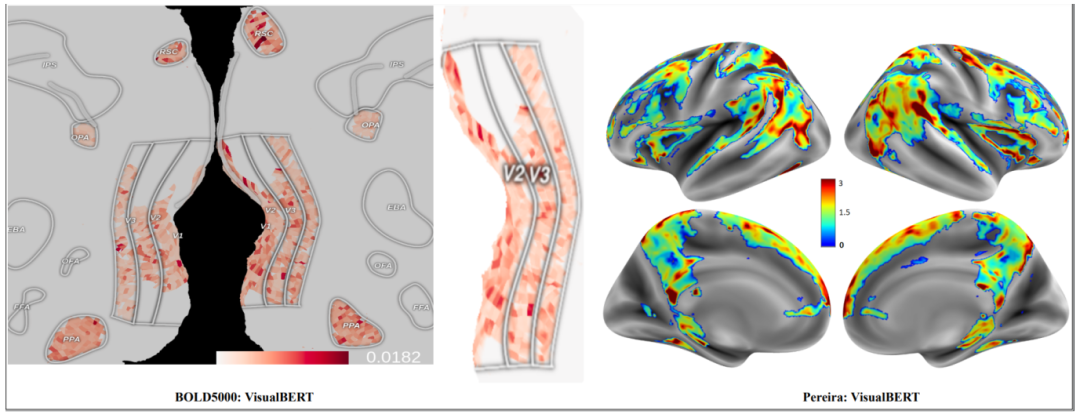
图5:实际体素和预测体素之间的MAE:(a)左图在BOLD5000受试者1上Visual-BERT的V2和V3脑区进行了放大。注意V1和V2也被称为EarlyVis区域,V3也被称为LOC区域。(b)右图是VisualBERT在Pereira数据集subject2上的图。
作为进一步的分析,在图5中展示了平均值。使用Visual-BERT在大脑区域中实际和预测体素之间的绝对误差(MAE)。与其他模型的类似脑图相比(见附录图12和图13),注意到大多数体素的误差幅度非常小。观察到,对于BOLD5000,EarlyVis区域的MAE值相对较高,OPA的MAE值最低。
模型大小与疗效的比较
在图3中绘制了BOLD5000中所有受试者的模型大小与Pearson相关性(PC)平均值的比较。观察到,与LXMERT相比,VisualBERT不仅更准确,而且也小得多。在大小几乎相同的情况下,VisualBERT与图像转换器相比要准确得多。最后,预训练的CNN比VisualBERT小,但即使使用的特定层激活是精挑细选的,准确度也较低。观察到Pereira数据集的类似趋势,如附录图7所示。
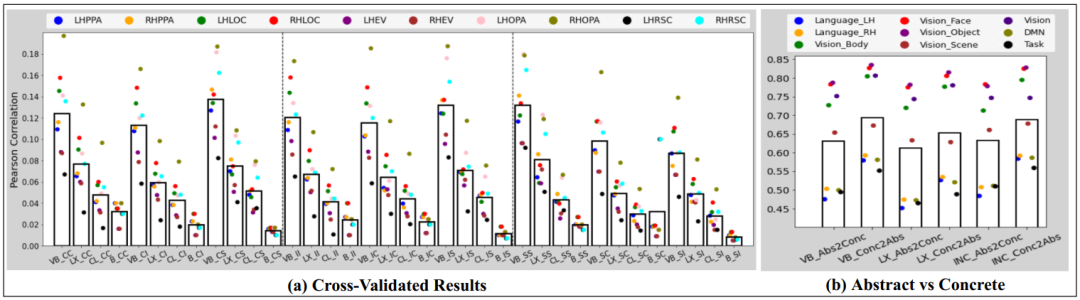
图6:(a)BOLD5000数据集的交叉验证结果。(b)Pereira数据集的抽象-具体结果。VB=VisualBERT,LX=LXMERT,CL=CLIP,B=baseline(Blauch等人,2019年),INC=InceptionV2ResNet。CC=Train and test on COCo,CI=Train on COCO and test on ImageNet,CS=Train on COCO and test on Scenes,等等)
交叉验证的MRI编码
图6(a)展示了使用三个多模态转换器(VisualBERT、LXMERT和CLIP)在BOLD5000上进行交叉验证编码的PC。展示了基线方法的结果,观察到:
(1)在所有交叉验证任务中,多模态转换器在所有5个脑区域的表现均优于基线结果。
(2)在对象选择视觉区LOC(外侧枕叶皮质),COCO训练和ImageNet测试的PC评分较高。
(3)同样,场景选择性脑区如RSC和OPA在coco-scene、ima genet-scene和scene-scene任务中具有较高的相关性。
(4)与其他脑区相比,早期视觉区在3个任务中相关性较低。
(5)总体而言,在COCO或Ima-geNet 上训练的模型比在场景上训练的模型报告更高的相关性。
抽象-具体的IRI编码
在图6(b)中,使用两个最好的多模态转换器(VisualBERT和LXMERT)和最好的预训练 CNN模型(In-ceptionV2ResNet),在大脑区域展示了abstract-train-concrete-test和concrete-train-abstract-test编码器模型的结果。观察到,与abstract-train-concrete-test模型相比,concrete-train-abstract-test模型提供了更好的PC评分。这与的预期相吻合,即的大脑从具体概念中学习得比从抽象概念中学习得更好。跨大脑区域的PC分析提供了以下见解。
(1)视觉脑区如Vision_Body、Vision_Face、Vision_Object和Vision对具体概念和抽象概念都有优越的表现;然而,这并不是Vision Scene区域的情况。
(2)在concrete-train-abstract-test模型中,语言、DMN和任务正(TP)脑网络的相关性高于abstract-train-concrete-test模型。
此外,在向参与者展示文本和图像的情况下,这些模型的性能自然很好,并且与Pere ira数据集的情况一样,全脑反应被捕获(见图4和图5(b))。基于计算实验的直觉,对未来的fMRI实验做了以下可测试的预测。如果参与者对物体场景执行命名任务/决策任务,而不是被动的观看任务,预计将看到更明显和集中的结果与被动观看相比,基于语言的任务中视觉区域的激活。
讨论
(1)尽管VisualBERT看起来性能很好,但它的尺寸相对较大。最近有很多关于压缩大型深度学习模型的工作,可以加以利用。
(2)尽管观察到VisualBERT导致了更好的结果,但它真的像大脑一样工作吗?计划在未来探索大脑体素空间和表征特征空间之间的相关性,以回答这个问题。
(3)在这项工作中探索了多模态刺激作为视觉和文本的组合。但联合强度(音频、视觉和文本)模态仍有待研究。
结论
具体而言,本文做出了以下贡献。
(1)给出了基于多模态变换器的最新编码结果,并研究了该模型在交叉验证设置下的有效性。
(2)生成了基于转换器的架构的使用,消除了在现有的基于CNN的fMRI编码架构中手动选择特定层的需要。
(3)揭示了关于fMRI体素和多模态/图像转换器和CNN的表征之间的关联的几个认知见解。计划将此作为未来工作的一部分进行探索。
附录
在表1和表2中分别展示了BOLD5000和Pereira数据集在不同大脑区域的实例数量和体素分布。
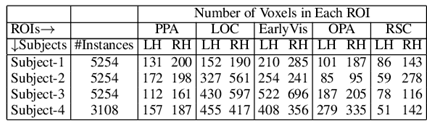
表1:BOLD5000数据集统计。LH =左半球。RH -右半球。
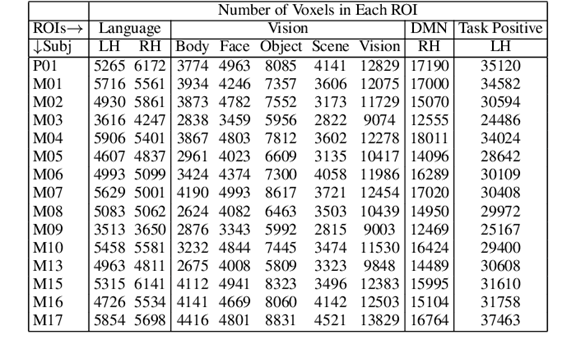
表2:Pereira数据集统计
预训练cnn的中间层表示相比,多模态变压器的编码性能
分别在图8和图9中的BOLD5000和Pereira两个数据集上,展示了使用从多模态转换器的最后一层提取的表示以及从预训练的CNN的所有低层到高层表示训练的模型的2V2准确度和Pearson相关性。
从图8中进行了以下观察:
(1)在2V2和Pearson 相关性方面,多模态转换器VisualBERT的表现优于所有预训练CNN的内部表示。
(2)在预训练的CNN中,与较低或较高级别的层表示相比,中间块具有更好的相关性评分.
(3)除了InceptionV2ResNet中的Conv2D150等中间块,其他多模态转换器CLIP和LXMERT与所有模型相比都有边缘改进。
从图9中进行了以下观察:
(1)在2V2和Pearson 相关性方面,多模态转换器VisualBERT的表现优于所有预训练CNN的内部表示。
(2)与BOLD5000相似,在Pereira数据集上预训练的CNN中,与较低或较高层次的层表示相比,中间块的相关性评分更好。
(3)其他多模态转换器,LXMERT,与每个预训练CNN模型的中间块具有相同的性能。
多模态转换器在它们的层中表现的编码性能
考虑到视觉或视觉语言信息跨转换器层的分层处理,进一步研究这些转换器层如何使用图像和多模态转换器编码fMRI大脑活动。分别在图10和图11中展示了BOLD5000和Pereira两个数据集上的分层编码性能结果。
从图10中进行了以下观察:
(1)多模态转换器Visu-alBERT在1到12层之间具有一致的性能。
(2)LXMERT模型的性能从中间层(L7)到高层有边际下降。
(3)图像变换具有较高的Pearson相关性,对于较低层次的早期视觉区域,而在较高层次的视觉区域,如LOC、OPA和PPA,相关性越来越强。
(4)表明人脑对视觉刺激的处理层次与图像转换器层相似。
从图11中进行了以下观察:
(1)多模态转换器VisualBERT在1到12层之间具有一致的性能。
(2)LXMERT模型的性能从较低的层到较高的层有边际递减。
(3)图像转换器ViT在较低层的早期视觉区域具有较高的Pearson相关性,而在较高层的视觉区域如VisionBody、Vision_Face和Vision_Obj具有较高的相关性。
BOLD5000数据集的各种模型的脑图
图12显示了BOLD5000数据集上各种模型的实际和预测体素之间的平均绝对误差(MAE),请注意,与图5(a)所示的Visual-BERT模型相比,大多数体素的误差幅度要高得多。此外,与图像转换器(MAE范围:0~0.02)和预训练CNN(MAE范围:0~0.0236)相比,多模态转换器VisaulBERT(MAE范围:0~0.0181)和LXMERT(MAE范围:0~0.0188)的MAE更低。
针对Pereira数据集的各种模型的脑图
图13显示了Pereira数据集上各种模型的实际体素和预测体素之间的平均绝对误差(MAE)。请注意,与图13(a)所示的VisualBERT模型相比,大多数体素的误差幅度要高得多。此外,与图像转换器和其他预训练的CNN相比,多模态转换器、VisaulBERT和LXMERT以及InceptionV2ResNet+Conv2D150的MAE更低。
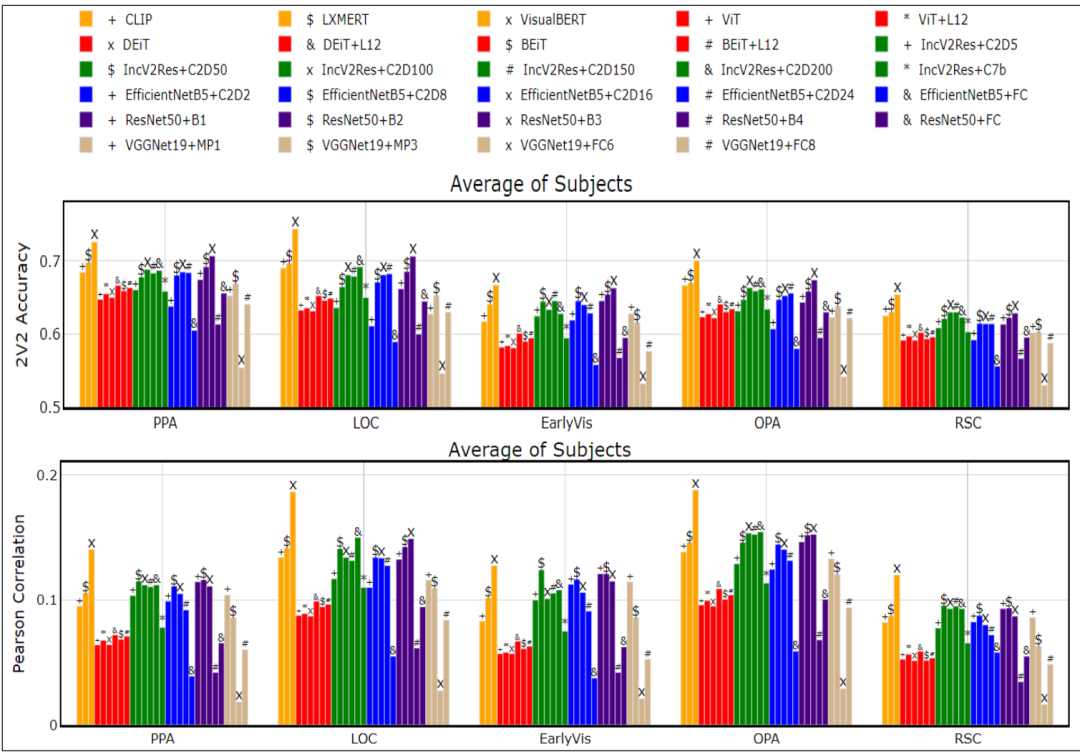
图8:BOLD5000: 2V2(顶部图)和Pearson相关系数(底部图)使用各种模型在不同大脑区域预测和真实反应之间的关系。结果是所有参与者的平均值。预训练的CNN结果显示所有层,而多模态转换器的结果只显示最后一层。
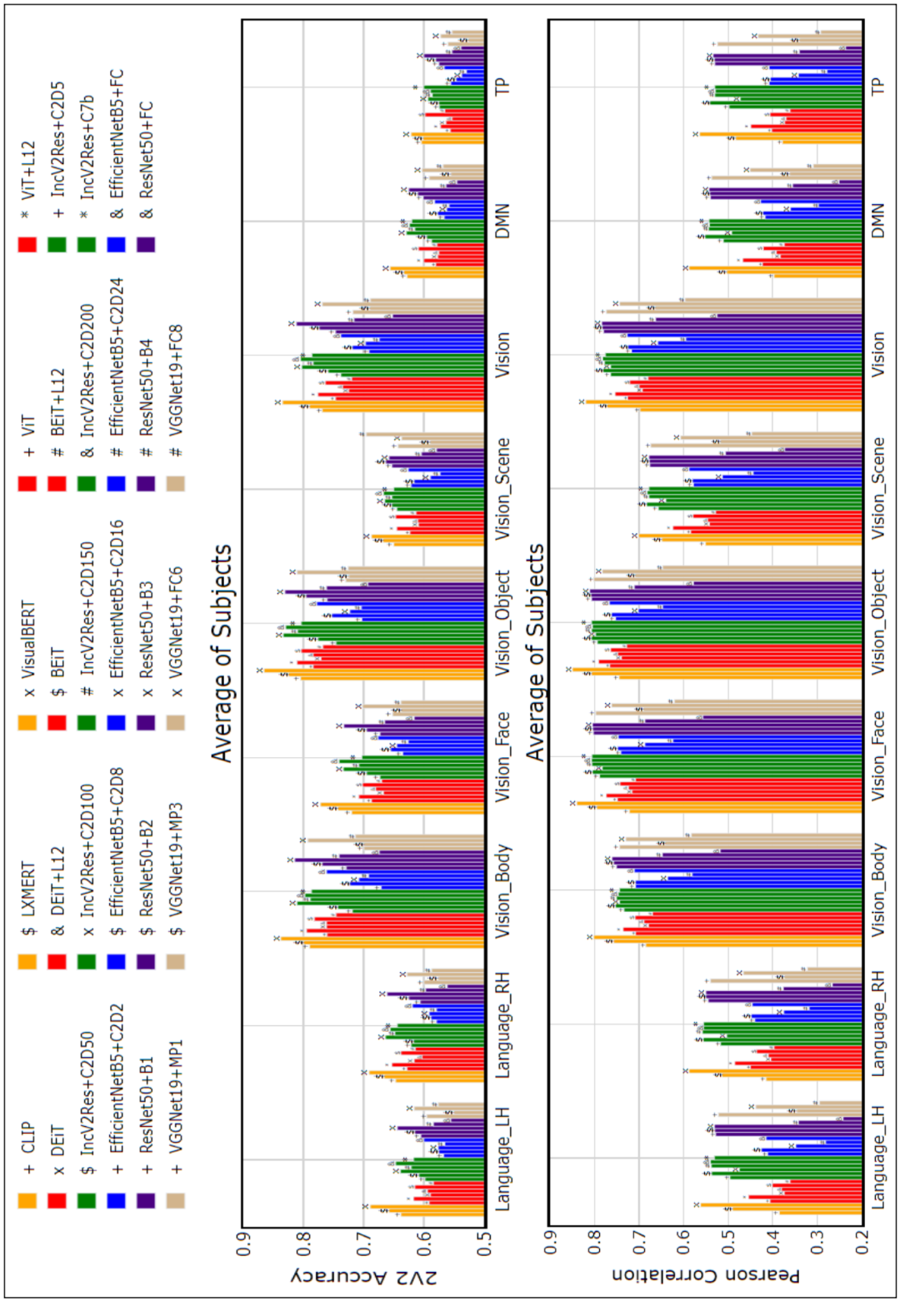
图9:Pereira数据集:2V2(上图)和Pearson相关系数(下图)使用各种模型在不同大脑区域预测和真实反应之间的关联系数。结果是所有参与者的平均值。预训练的CNN结果显示所有层,而多模态转换器的结果只显示最后一层。
更多相关内容
-
无区域集团股份公司名称办理费用及条件介绍
无区域集团股份公司名称办理费用及条件介绍 韩冷锋15301056225 不含行政区划不含行业表述的名称,...
-
转让一家50万注册资金的公司带北京车指标牌照
转让一家 50 万注册资金的公司带北京车指标牌照 韩冷锋15301056225
-
华发股份:构筑稳健增长“护城河”
全文约3500字,阅读全文大约需要10分钟 引言 在新的行业周期下,亿翰智库关注到衡量一家企业是...
-
重磅丨2022年6月全国各区域典型房企稳健发展指数研究①
2022年6月,亿翰智库监测各房企发展情况,发布区域典型房企稳健发展指数研究成果 ,与行业、区域房...
-
成立政企业务线
7月12日,腾讯云与智慧产业事业群(CSIG)宣布成立政企业务线,持续深耕政务、工业、能源、文旅、农业、...
-
以海关监管物作为租赁物是否违反监管规定
本文作者为申骏律师事务所袁雯卿、许建添 来源:金融争议观察 在以动产设备作为租赁物的融资...
-
总投资6.1亿,床位数650张,重庆市残疾人康复中心和重庆医科大学附属康复医院一期项目年底投用
由重庆市
-
CHCC2022医院考察——开业半年即获鲁班奖的武汉协和医院金银湖院区
2022年7月23-25日,由筑医台、国药励展、中国医学装备协会医院建筑与装备分会、筑而瑞联
-
房企频频暴雷,如何保住现金流
本作品获2022帆软BI数据分析大赛【最佳行业应用奖】 获奖 团队:美女与和平 队员:赖石娇(队长)、...
-
无区域中字头控股公司转让控股集团公司转让
无区域中字头控股公司转让控股集团公司转让 I88拨ll47打0405 姚经理 公司现有无区域中字...






推荐阅读








