
产业新知热门
 加国央行再次疯狂加息 月供将暴涨 物价竟会这样变化
加国央行再次疯狂加息 月供将暴涨 物价竟会这样变化
 无人幸免的购物节“大逃杀”
无人幸免的购物节“大逃杀”
 兼职做自媒体这些天:有人年入五块四,有人时薪一百二
兼职做自媒体这些天:有人年入五块四,有人时薪一百二
 瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
 武汉大学疑似出现霍乱病例
武汉大学疑似出现霍乱病例
 期货不严格止损是超短线交易失败的根源
期货不严格止损是超短线交易失败的根源
 ,精细赛道也能走到上市!
,精细赛道也能走到上市!
 预制菜,会有“刺客”吗
预制菜,会有“刺客”吗

推荐资讯
让区块链变成人人可用的工具,上海原创Web3.0操作系统是如何诞生的
隐私之变|自我主张时代变革,从构建WEB3.0的ID体系开始
被投资圈盯上,风头超过元宇宙,Web3.0到底是啥?
Web3.0,勾勒下一代互联网模样
为什么说中国汽车产业已经真正“支棱”起来了
我在新能源汽车行业打工10年:从月薪2千涨至年薪40万,终于熬出头
对话梅宏院士:数字化转型不是想不想,而是必须转
王兴继续“电商零售梦”:告别社区团购 美团优选变身明日达超市

Papers & Radios | CVPR 2022最佳/最佳学生论文;大型语言模型教会智能体进化
 财经快报
|
2022/08/22 19:37:40
财经快报
|
2022/08/22 19:37:40
来源:机器之心
目录
-
Learning to Solve Hard Minimal Problems
-
Dual-Shutter Optical Vibration Sensing
-
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
-
Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields
-
Self-supervised Transparent Liquid Segmentation for Robotic Pouring
-
Neural Label Search for Zero-Shot Multi-Lingual Extractive Summarization
-
Evolution through Large Models
-
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Learning to Solve Hard Minimal Problems
-
作者:Petr Hruby等
-
论文链接:https://arxiv.org/abs/2112.03424
摘要:该研究提出了一种在 RANSAC 框架中解决困难的几何优化问题的方法。最小化问题源于将原始几何优化问题松弛化为具有许多虚假解决方案的最小问题。该研究提出的方法避免了计算大量虚假解决方案。
研究者设计了一种学习策略,用于选择初始问题 - 解决方案对以用数值方法继续解决原问题。该研究通过创建一个 RANSAC 求解器来演示所提方法,该求解器通过使用每个视图中的 4 个点进行最小松弛化来计算 3 个校准相机的相对位姿。平均而言,该方法可以在 70 μs、内解决一个原始问题。此外,该研究还针对校准相机的相对位姿这一问题进行了基准测试和研究。
内部 RANSAC 循环为数据样本 p 找到最佳解决方案。
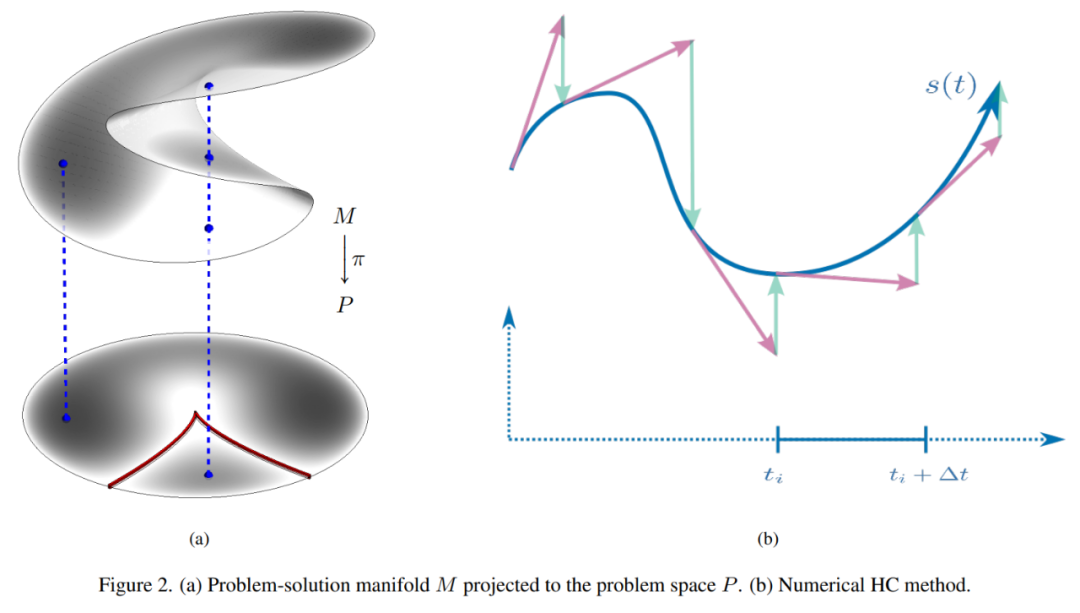
(a) 映射到问题空间 P 的问题解决流形 M;(b) 数值 HC 方法。
分类器评估。
推荐:CVPR 2022 最佳论文。
论文 2:Dual-Shutter Optical Vibration Sensing
-
作者:Mark Sheinin 等
-
论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Sheinin_Dual-Shutter_Optical_Vibration_Sensing_CVPR_2022_paper.pdf
摘要:视觉振动测量是一种非常有用的工具,可用于远程捕捉音频、材料物理属性、人体心率等。虽然视觉上可观察的振动可以通过高速相机直接捕捉,通过将激光束照射振动表面所产生的散斑图案的位移成像,可以从光学上放大微小且不易察觉的物体振动。
在本文中,研究者提出了一种在高速(高达 63 kHz)下同时检测多个场景源振动的新方法,该方法使用额定工作频率仅为 130Hz 的传感器。他们的方法使用两个分别配备滚动和全局快门传感器的相机来同时捕捉场景,其中滚动快门相机捕捉到对高速物体振动进行编码的失真散斑图像,全局快门相机捕捉散斑图案的未失真参考图像,从而有助于对源振动进行解码。最后,研究者通过捕捉音频源(如扬声器、人声和乐器)引起的振动并分析音叉的振动模式,展示了他们的方法。
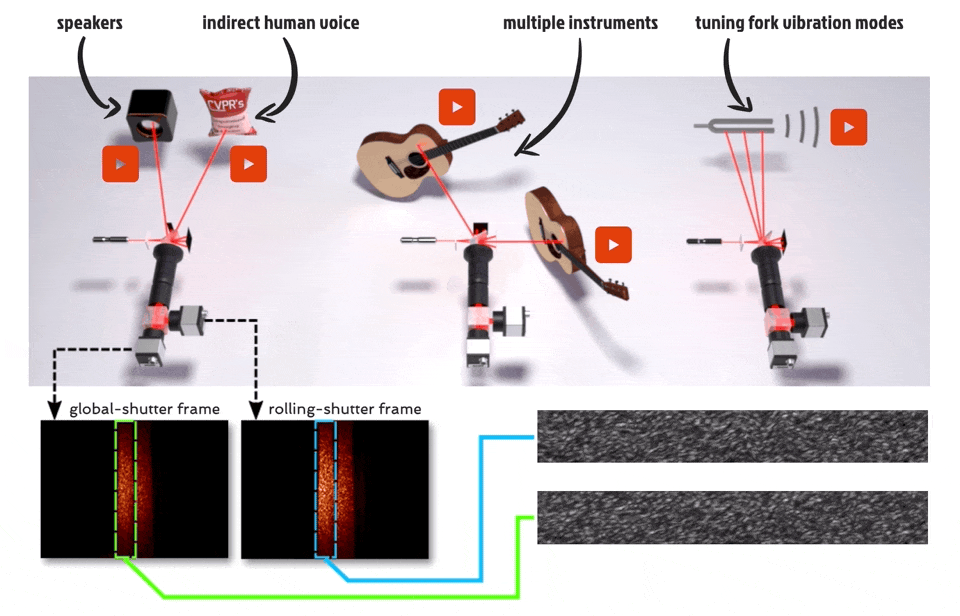
研究者用一种新颖的方法「看到」(seeing)声音。
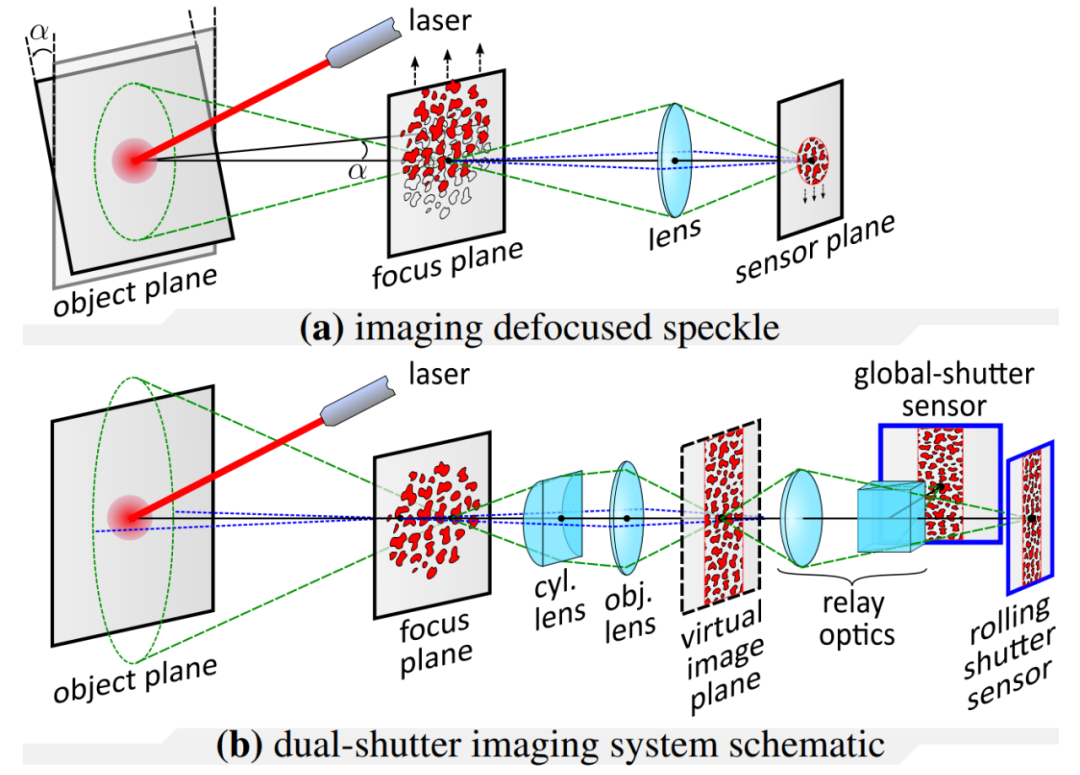
(a) 成像散焦散斑;(b) 双快门成像系统示意图。
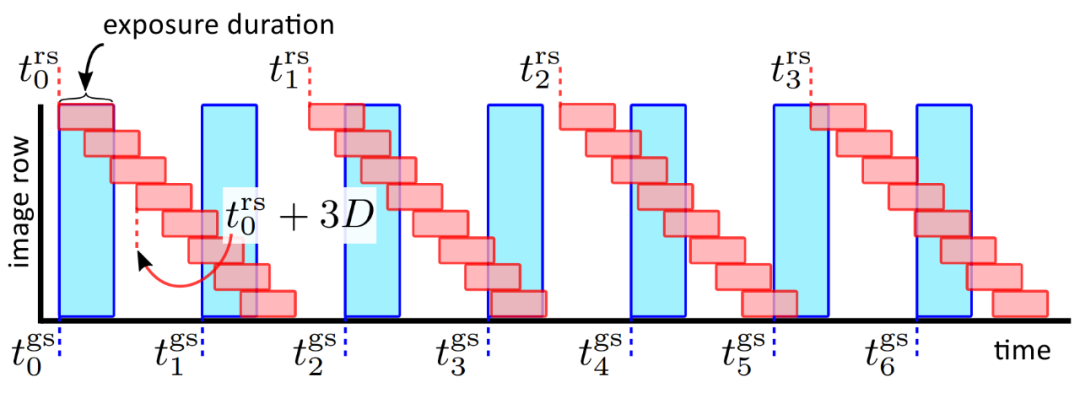
双快门相机定时。
推荐:CVPR 2022 最佳论文提名。
论文 3:EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
-
作者:Hansheng Chen 等
-
论文链接:
-
https://arxiv.org/pdf/2203.13254.pdf
摘要:利用透视点(PnP)基数从单个 RGB 图像中定位 3D 物体是计算机视觉领域一个长期存在的问题。在端到端深度学习的驱动下,近期的研究建议将 PnP 解释为一个可微分层,如此 2D-3D 点对应就可以部分地通过反向传播梯度 w.r.t. 物体姿态来学习。然而,从零开始学习整套不受限的 2D-3D 点在现有的方法下很难收敛,因为确定性的姿态本质上是不可微的。
这篇论文提出了一种用于普遍端到端姿态估计的概率 PnP 层 ——EPro-PnP(end-to-end probabilistic PnP),它在 SE 流形上输出姿态的分布,实质地将分类 Softmax 带入连续域。2D-3D 坐标和相应的权值作为中间变量,通过最小化预测姿态与目标姿态分布之间的 KL 散度来学习。其基本原理统一了现有的方法,类似于注意力机制。EPro-PnP 的性能明显优于其他基准,缩小了基于 PnP 的方法与基于 LineMOD 6DoF 的姿态估计以及 nuScenes 3D 目标检测基准的特定任务方法之间的差距。
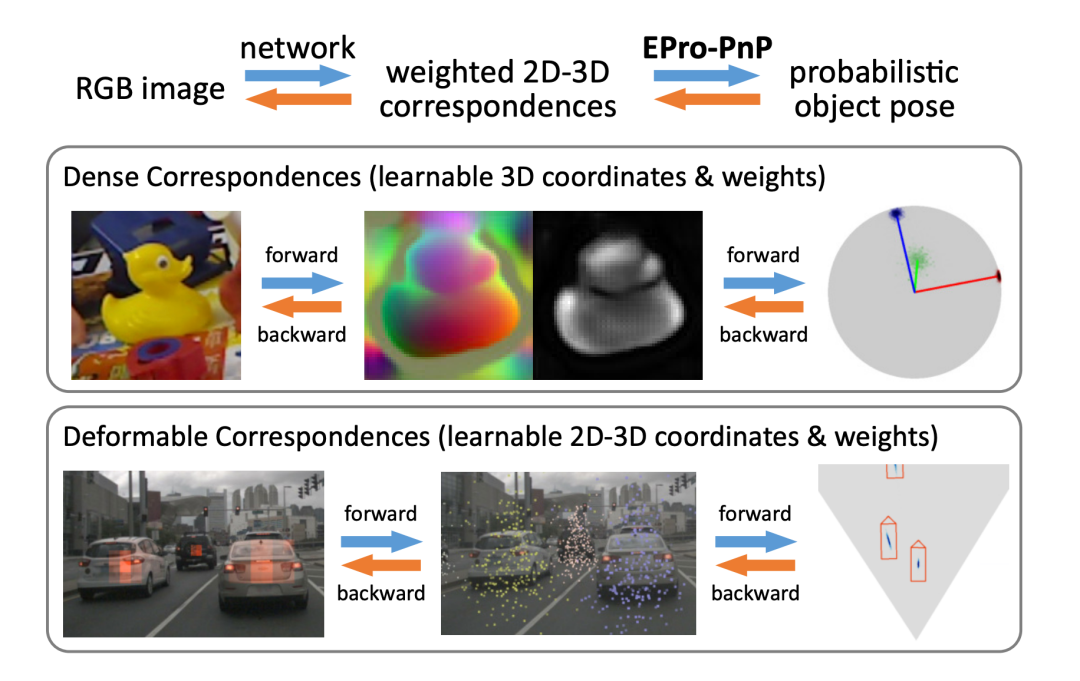
EPro-PnP 方法概览。
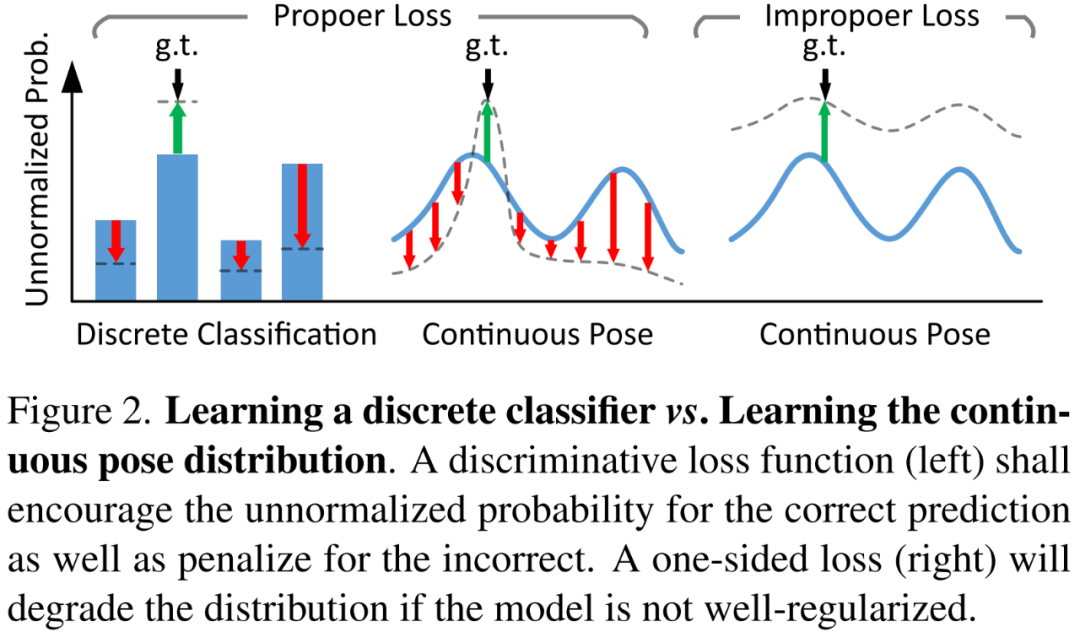
学习离散分类器 vs 学习连续姿态分布。

算法 1:基于 AMIS 的蒙特卡洛姿态损失。
推荐:CVPR 2022 最佳学生论文。
论文 4:Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields
-
作者:Dor Verbin 等
-
论文链接:
-
https://arxiv.org/pdf/2112.03907.pdf
摘要:神经辐射场是一种流行的视图合成技术,它将场景表示为连续的体积函数,由多层感知器参数化,多层感知器提供每个位置的体积密度和与视图相关的散发辐射。虽然基于 NeRF 的方法擅长表征平滑变化的外观几何结构,但它们通常无法准确捕捉和再现光泽表面的外观。
该研究提出了 Ref-NeRF 来解决这个问题,它将 NeRF 与视图相关的散发辐射的参数化替换为反射辐射的表征,并使用空间变化的场景属性的集合来构造该函数。该研究表明,使用法向量上的正则化器,新模型显著提高了镜面反射的真实性和准确性。此外,该研究还表明该模型对散发辐射的内部表征是可解释的,这对于场景编辑非常有用。

与以往表现最好的神经视图合成模型 mip-NeRF 相比,Ref-NeRF 显著提升了法向量(最上行)和视觉真实性(余下行)。
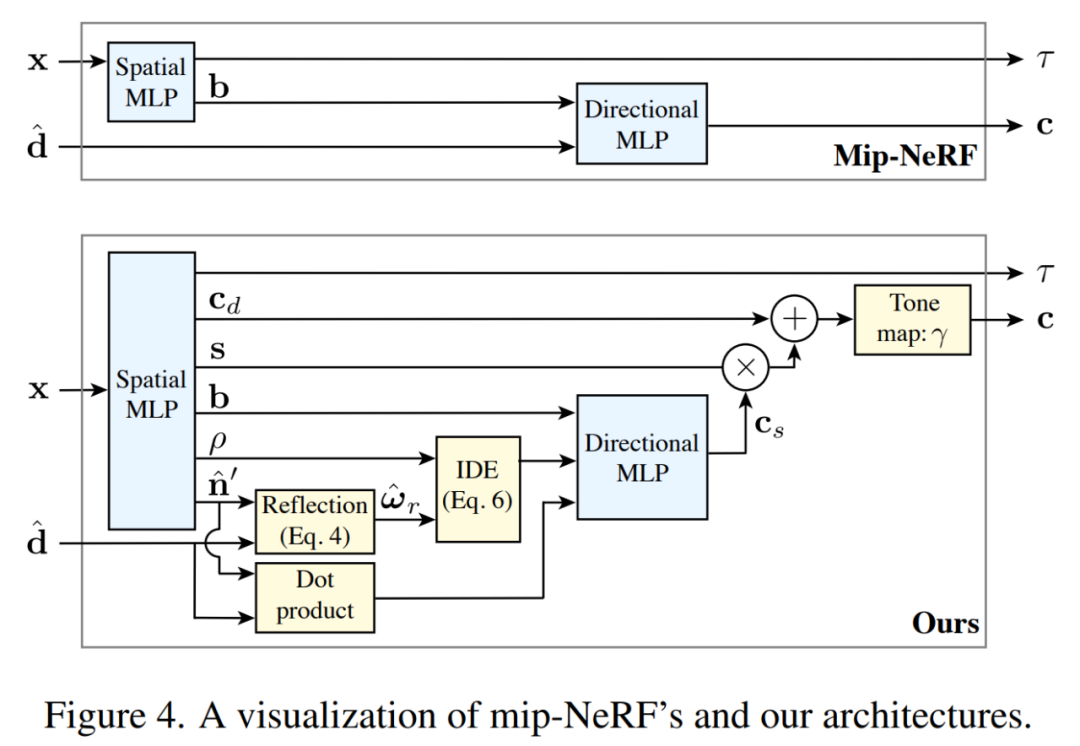
mip-NeRF(上)和 Ref-NeRF(下)的架构图比较。
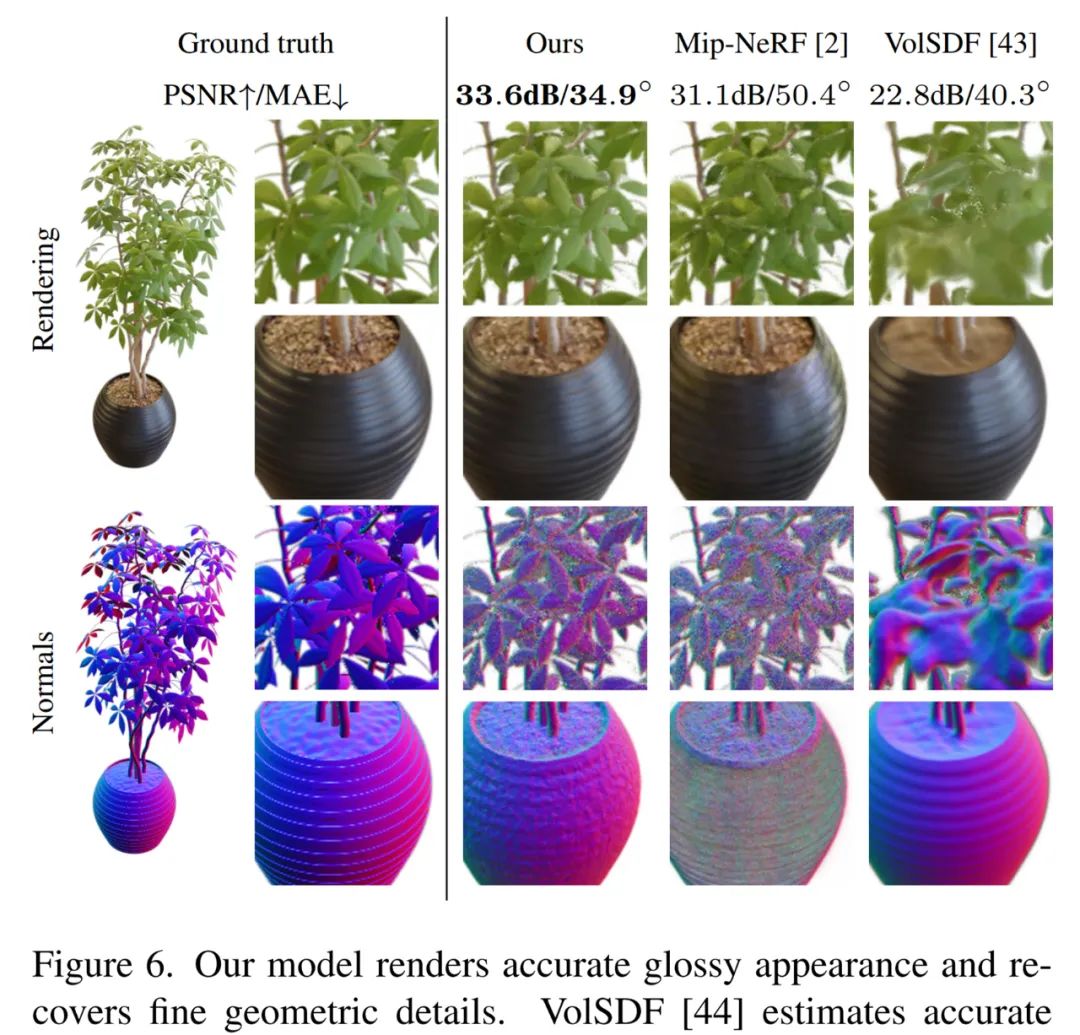
Ref-NeRF 渲染出准确的光鲜表面,覆盖精细几何细节。
推荐:CVPR 2022 最佳学生论文提名。
论文 5:Self-supervised Transparent Liquid Segmentation for Robotic Pouring
-
作者:Gautham Narasimhan 等
-
论文链接:
https://arxiv.org/pdf/2203.01538.pdf
摘要:近期,在 CMU 和圣母大学的一篇论文中,研究者提出了一种在透明容器中感知透明液体(水)的方法。与以往方法相比,本研究提出的方法减轻了对操作域的限制。具体地,他们在单个图像上进行操作,不需要液体运动或多帧,也不需要在训练期间进行手动注释或加热液体。研究者使用一个生成模型来学习将有色液体的图像转换为透明液体的合成图像,这种做法可以用来训练透明的液体细分模型。
论文一作 Gautham Narasimhan 现为 CMU 机器人研究所的助理研究员,2020 年在 CMU 拿到了硕士学位。目前,他致力于研究用于机器人倒水任务的强化学习模型。该研究由 LG Electronics 和美国国家科学基金会提供资助,并于 5 月份发表在 IEEE 国际机器人和自动化会议上。该论文已被机器人领域国际顶会 ICRA 2022 接收。
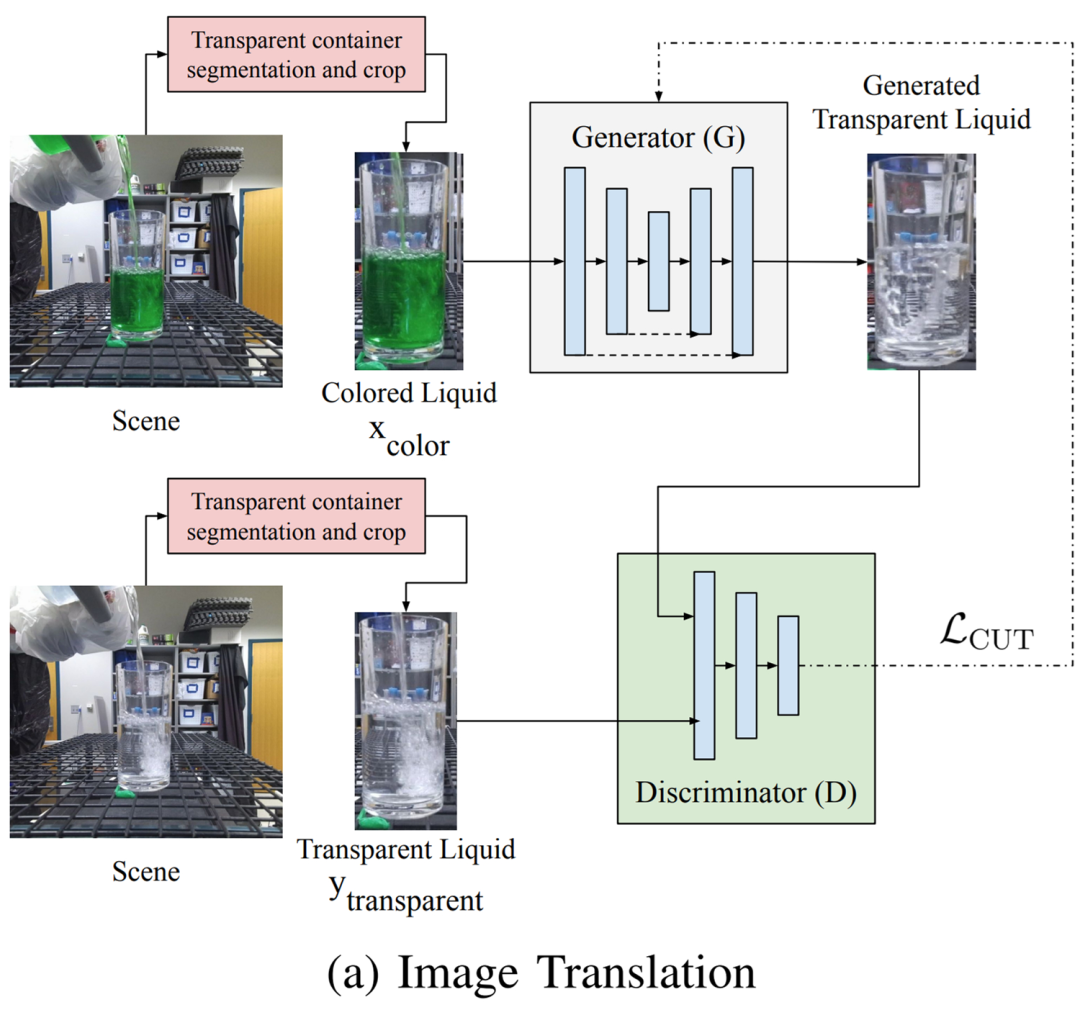
有色液体图像转换成透明液体图像的详细流程图。
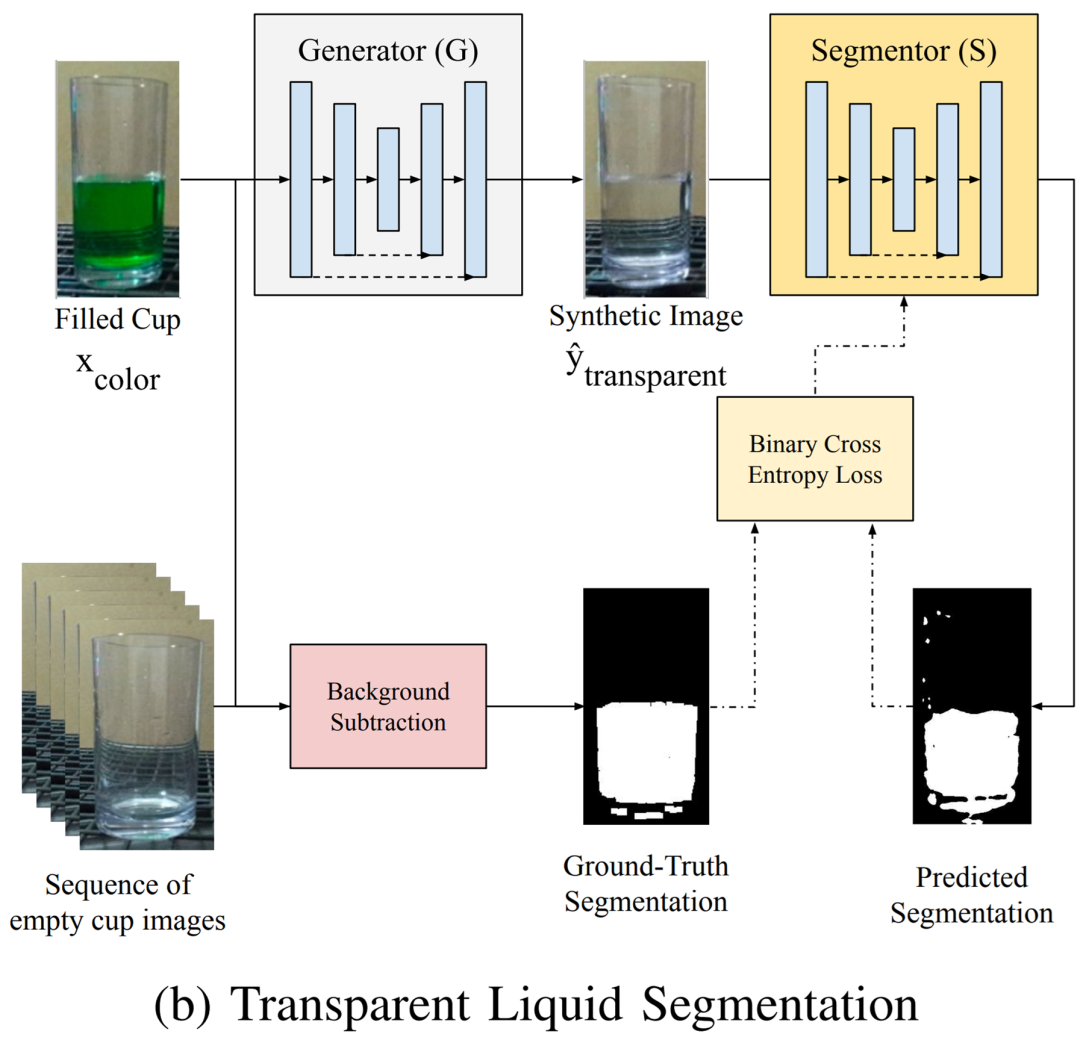
透明液体细分流程图。
推荐:将有色液体图像转换成透明液体,CMU 教机器人准确掌控向杯中倒多少水。
论文 6:Neural Label Search for Zero-Shot Multi-Lingual Extractive Summarization
-
作者:Ruipeng Jia 等
-
论文链接:
https://aclanthology.org/2022.acl-long.42.pdf
摘要:抽取式文本摘要目前在英文上已经取得了很好的性能,这主要得益于大规模预训练语言模型和丰富的标注语料。但是对于其他小语种语言,目前很难得到大规模的标注数据。中国科学院信息工程研究所和微软亚洲研究院联合提出一种是基于 Zero-Shot 的多语言抽取式文本摘要模型。具体方法是使用在英文上预训练好的抽取式文本摘要模型来在其他低资源语言上直接进行摘要抽取;并针对多语言 Zero-Shot 中的单语言标签偏差问题,提出了多语言标签标注算法和神经标签搜索模型。
实验结果表明,模型 NLSSum 在多语言摘要数据集 MLSUM 的所有语言上大幅度超越 baseline 模型的分数。其中在俄语(Ru)数据集上,零样本模型性能已经接近使用全量监督数据得到的模型。该研究发表在了 ACL 2022 会议主会长文上。

多语言 Zero-Shot 中的单语言标签偏差问题。
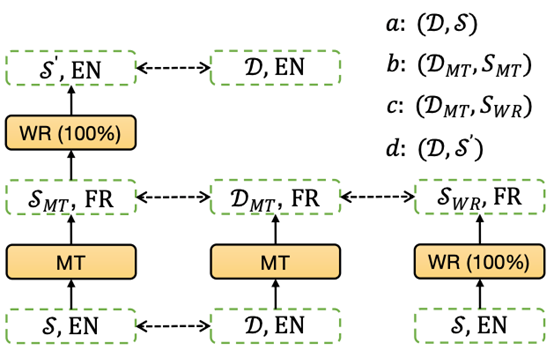
多语言标签。
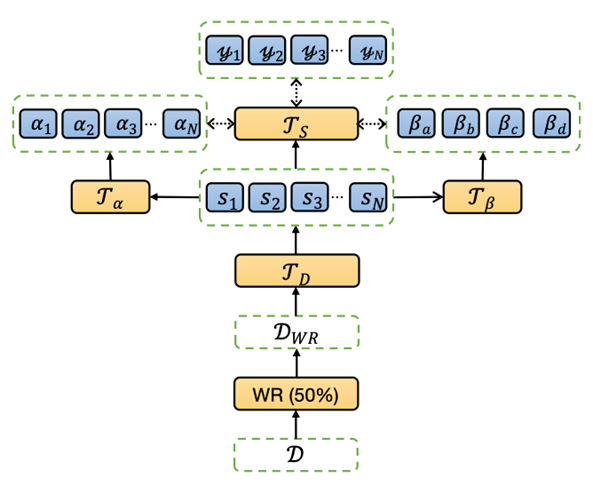
多语言神经标签搜索摘要模型。
推荐:基于神经标签搜索,中科院 & 微软亚研零样本多语言抽取式摘要入选 ACL 2022。
论文 7:Evolution through Large Models
-
作者:Joel Lehman 等
-
论文链接:https://arxiv.org/abs/2206.08896
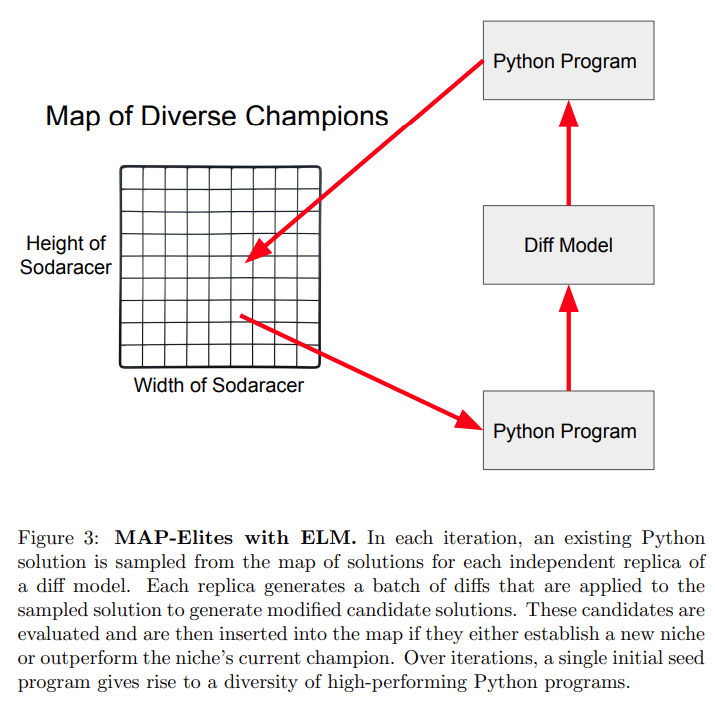
摘要:很难想象,让大型语言模型辅助一下智能体机器人,它就自己成精了...... 深度学习和进化计算两种方法都适用于计算,都可以产生有用的发现和有意义的进展。不过,二者之间到底是相互竞争的模式,还是互补的模式?最近一篇论文中,来自 OpenAI 的研究者探讨了第二种情况,即互补模式的可能性。他们研究了大语言模型 (LLM; [1,2]) 在基因编程 (GP; [3,4]) 和开放性 [5-7] 上的潜在意义,发现了二者间的协同作用。
该研究选择使用 MAP-Elite 算法进行实验。
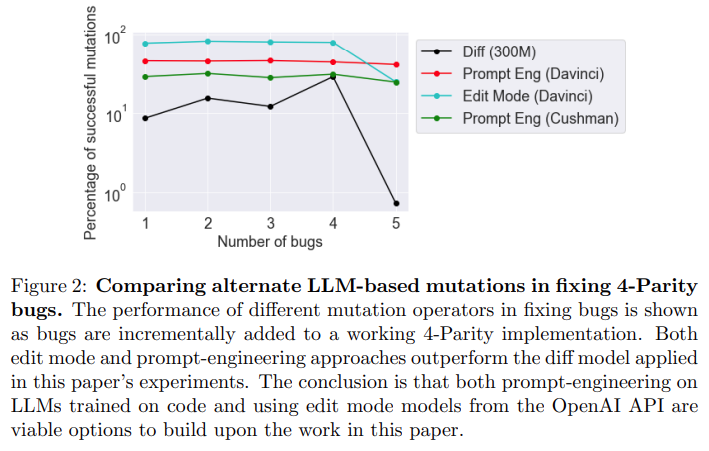
来自 OpenAI API 的模型优于论文中的 diff 模型。
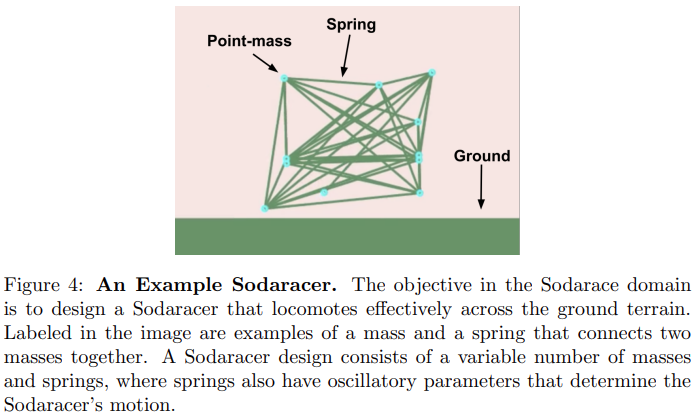
一个单独的 Sodaracer 由一个大小可变的点质量(point mass)集合 (每个点质量都由其初始的 2D 位置描述) 和将质量连接在一起的振荡弹簧组成。
更多相关内容
-
马毅沈向洋曹颖最新AI综述火了!耗时3月打造,网友:必读论文
千呼万唤始出来,马毅教授的AI综述论文终于出炉! 耗时三个多月,联合神经科学家曹颖、计算机大牛沈向...
-
CloudX云智能学院丨人工智能技术图谱,AI高阶——顶会论文
由阿里云天池倾力打造的AI技术学习图谱,配套有免费算力、珍稀数据集,钉钉群答疑等资源和服务,助力学...
-
深度学习论文精读[GAN]:利用深度生成先验进行多用途图像修复与处理
笔者最近在集中时间学习 对抗生成网络(GAN) ,特别是深度生成先验进行多用途图像修复与处理,...
-
卧槽,卷王之王呀!又一个论文神器
笔者最近在集中时间学习 对抗生成网络(GAN) ,特别是深度生成先验进行多用途图像修复与处理,...
-
深度学习论文精读[GAN]:利用深度生成先验进行多用途图像修复与处理
笔者最近在集中时间学习 对抗生成网络(GAN) ,特别是深度生成先验进行多用途图像修复与处理,...
-
发论文拿推荐信的机会来了!哥大,宾大导师金融科研项目请招生!
如果你对上面的项目感兴趣 请长按识别下方二维码添加顾问老师微信咨询 并发送专属口令【431金融学综...
-
把理论文章发表到《现代教育报》上该怎么做
《现代教育报》是中宣部和国家新闻总署批准的面向国内外公开发行的大型综合性教育报。报以教育新闻为核...
-
【MIT博士论文】数据高效强化学习
本周重要论文包括:CVPR 2022各种获奖论文。强化学习(Reinforcement learning, RL)是一种学习复杂决策策...
-
【留学经验贴】从双非到港科,论文助我一臂之力
“ 人生中重要的选择,通常都是在对未来认知不全面的时候做下的。如果 对真实求职过程的信息掌握...
-
发论文拿推荐信!最新AI机器学习算法方向科研项目招生!
人类能够从经验中学习,并随着更多的经验和更多的数据,从而更出色地完成自己的任务。其中,有一个重要...






推荐阅读








