
产业新知热门
 加国央行再次疯狂加息 月供将暴涨 物价竟会这样变化
加国央行再次疯狂加息 月供将暴涨 物价竟会这样变化
 无人幸免的购物节“大逃杀”
无人幸免的购物节“大逃杀”
 兼职做自媒体这些天:有人年入五块四,有人时薪一百二
兼职做自媒体这些天:有人年入五块四,有人时薪一百二
 瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
 武汉大学疑似出现霍乱病例
武汉大学疑似出现霍乱病例
 期货不严格止损是超短线交易失败的根源
期货不严格止损是超短线交易失败的根源
 ,精细赛道也能走到上市!
,精细赛道也能走到上市!
 预制菜,会有“刺客”吗
预制菜,会有“刺客”吗

推荐资讯
让区块链变成人人可用的工具,上海原创Web3.0操作系统是如何诞生的
隐私之变|自我主张时代变革,从构建WEB3.0的ID体系开始
被投资圈盯上,风头超过元宇宙,Web3.0到底是啥?
Web3.0,勾勒下一代互联网模样
为什么说中国汽车产业已经真正“支棱”起来了
我在新能源汽车行业打工10年:从月薪2千涨至年薪40万,终于熬出头
对话梅宏院士:数字化转型不是想不想,而是必须转
王兴继续“电商零售梦”:告别社区团购 美团优选变身明日达超市

快MAE3.1倍、BEiT5.3倍!基于局部mask重建的高效自监督视觉预训练方法LoMaR,同时提高训练精度和效率!
 财经快报
|
2022/08/30 12:18:51
财经快报
|
2022/08/30 12:18:51
本篇分享论文 『Efficient Self-supervised Vision Pretraining with Local Masked Reconstruction』 ,比MAE快3.1倍,比BEiT快5.3倍!KAUST&南洋理工提出基于局部mask重建的高效自监督视觉预训练方法LoMaR,同时提高训练精度和效率!
详细信息如下:

-
论文地址:https://arxiv.org/abs/2206.00790
01
摘要
计算机视觉的自监督学习取得了巨大的进步,改进了许多下游视觉任务,如图像分类、语义分割和目标检测。其中,MAE和BEiT等生成性自监督视觉学习方法表现出了良好的性能。然而,它们的全局掩蔽重建机制对计算的要求很高。
为了解决这个问题,作者提出了局部掩蔽重建(local masked reconstruction,LoMaR),这是一种简单而有效的方法,在一个简单的Transformer编码器上,在7×7块的小窗口内执行掩蔽重建,与整个图像的全局掩蔽重建相比,提高了效率和精度之间的权衡。
大量实验表明,LoMaR在ImageNet-1K分类中达到84.1%的top-1精度,优于MAE 0.5%。在384×384图像上对预训练后的LoMaR进行微调后,可以达到85.4%的top-1精度,超过MAE 0.6%。在MS COCO上,LoMaR在目标检测上比MAE好0.5
,在实例分割上比MAE好0.5 。LoMaR在预训练高分辨率图像上的计算效率尤其高,例如,在预训练448×448图像上,LoMaR比MAE快3.1倍,分类精度高0.2%。这种局部掩蔽重建学习机制可以很容易地集成到任何其他生成性自监督学习方法中。02
Motivation
最近,自监督学习方法在学习有利于下游应用的表示方面取得了巨大成功,如图像分类和目标检测。其中,几种生成性自监督学习方法,如MAE和BEiT,它们从一小部分图像块重建输入图像,表现出了优异的性能。
然而,像MAE和BEiT这样的生成式自监督学习算法的一个主要瓶颈是它们对计算的要求很高,因为它们具有全局掩蔽重建,并且对大量图像块进行操作。例如,在128个TPU-v3 GPU上,对120万张分辨率为224×224的ImageNet图像进行MAE-Huge预训练需要34.5小时。
由于离散变分自动编码器的相关成本,BEiT训练速度较慢。高分辨率图像进一步加剧了这一问题。例如,在384×384图像上预训练MAE消耗的计算时间是224×224对应图像的4.7倍。然而,高分辨率图像在许多任务中是必不可少的,例如目标检测。因此,提高预训练的效率是至关重要的。

在Transformer模型中,全局自注意机制关注所有n个图像patch,产生
的时间复杂度。但是,在重建过程中attend远距离的patch的好处仍不清楚。在上图中,作者可视化了重建mask图像patch时的注意权重。从预训练的 模型中,从解码器层2、4、6和8中提取注意权重,并使用白色表示高注意力值。该模型主要attend目标patch附近的patch,这促使作者限制重建中使用的注意力范围。因此,本文提出了一种新的模型,称为局部掩蔽重建或LoMaR。该模型将注意力区域限制在一个小窗口内,如7×7的图像块,这足以进行重建。对于那些需要在长序列上操作的任务,在许多NLP领域中也可以看到类似的方法。在视觉领域也探索了小窗口,以提高训练和推理速度。但与之前的视觉Transformer(如Swin Transformer)不同,Swin Transformer为每个图像创建具有固定坐标的移动窗口。本文取而代之的是对几个随机位置的窗口进行采样,这样可以更好地捕获不同空间区域中的对象。
在下图中,作者比较了LoMaR和MAE,并注意到两个主要区别:a)本文对一个区域进行了k×k个patch采样,以进行掩蔽重建,而不是从全部patch中进行重建。作者发现,只需一些局部视觉线索,就足以恢复丢失的信息,而不是从图像中全局25%的可见patch重建遮罩patch。b) 本文将MAE中的重量级解码器替换为轻量级MLP头。将所有图像patch直接输入编码器,包括masked和visible patches。相比之下,在MAE中,只有可见的patch被馈送到编码器。实验表明,这些结构变化为小窗口的局部掩蔽重建带来了更大的性能增益。
经过广泛的实验,作者发现
-
LoMaR在ImageNet-1K数据集上可以实现84.1 top-1 acc,比MAE高出0.5 acc。此外,LoMaR的性能可以进一步提高到84.3 acc,在ViT B/8主干上只需预训练400个阶段,与ViT B/16相比,这不会带来额外的预训练成本。在分辨率为384×384的图像上对预训练模型进行微调后,LoMaR可以达到85.4 acc,比MAE高出0.6 acc。
-
LoMaR在高分辨率图像预训练中比其他baseline更有效,因为它的计算量对不同的图像分辨率是不变的。然而,其他方法的计算成本是图像分辨率增加的二次方,这导致了昂贵的预训练。比如,对于448×448图像的预训练,LoMaR比MAE快3.1倍,实现了更高的分类性能。
-
LoMaR是一种高效的学习方法,可以很容易地集成到任何其他生成性自监督学习方法中。将本文的局部掩蔽重建学习机制安装到BEiT中可以将其ImageNet-1K分类性能从83.2提高到83.4,只消耗最初预训练时间的35.8%。LoMaR在其他任务(如目标检测)上也具有很强的泛化能力。在ViTDet的目标检测框架下,它比MAE的性能高出0.5
。
03
方法
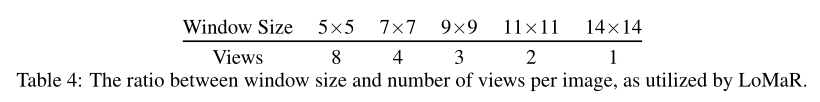
LoMaR依赖于一堆Transformer块,通过从与MAE类似的损坏图像中恢复缺失的patch来预训练大量未标记图像,但LoMaR在几个关键位置将其与MAE区分开来。上图并排比较了两者。在本节中,作者首先回顾MAE模型,然后描述LoMaR和MAE之间的差异。
3.1 Background: Masked Autoencoder :
上图左侧所示的掩蔽自动编码器(MAE)模型,采用非对称编码器-解码器架构。编码器从图像中获取patch的子集,并输出patch的潜在表示。根据这些,解码器重建缺失的patch。对于分辨率为h×w的输入图像,MAE首先将其划分为一系列不重叠的patch。然后,MAE随机屏mask了大部分(例如75%)图像patch。将位置编码添加到每个patch以指示其空间位置。MAE首先将剩余的patch编码到潜在表示空间中,然后将潜在表示与mask patch的占位符一起提供给解码器,解码器执行重建。对于每个重建图像,MAE使用像素空间中原始图像的均方误差(MSE)作为损失函数。
3.2 Local Masked Reconstruction (LoMaR) :
Local vs. Global Masked Reconstruction
MAE使用从整个图像中采样的patch重建每个缺失的patch。然而,如图1所示,通常只有目标patch附近的patch对重建有显著贡献,这表明局部信息足以用于重建。因此,作者对小区域内的patch进行掩蔽和重建。实验发现,区域大小为7×7的patch可以在精度和效率之间取得最佳的平衡。另一方面,与卷积网络类似,LoMaR具有平移不变性,因为每次迭代都使用在随机空间位置采样的小窗口。
从复杂性的角度来看,由于用于操作的token较少,局部掩蔽和重构比全局掩蔽和重构MAE在计算效率上更高。假设每个图像可以划分为h×w个patch。计算自注意的时间复杂度为
。复杂度与patch数量呈二次关系。然而,对于本文的局部掩蔽重建,采样n个窗口,其中每个窗口包含m×m个patch;其计算复杂度为 ,如果将m×m固定为一个恒定的窗口大小,则其时间复杂度为线性。如果 ,计算复杂度将显著降低。Architecture
LoMaR采用了一种简单的编码器-编码器结构,而不是MAE的非对称编码器-解码器。作者将采样区域下所有可见和mask的patch输入编码器。虽然将mask patch输入编码器可能被认为是比仅将mask patch输入解码器的MAE效率更低的操作,但作者发现,在早期阶段输入mask patch可以增强视觉表现,并使其对较小的窗口大小更具鲁棒性。这可能是因为编码器可以在多个编码器层与其他可见patch交互后,将mask patch转换回其原始RGB表示。隐藏层中恢复的mask patch可以隐式地对图像表示作出贡献。因此,本文在LoMaR中保留mask patch作为编码器输入。
Relative positional encoding
LoMaR在MAE中应用相对位置编码(RPE)而不是绝对位置编码。作者应用了上下文RPE,在计算自注意时,它为每个查询i和键j引入了一个可学习的向量
。Implementation
给定一幅图像,首先将其划分为几个不重叠的patch。每个patch线性投影到嵌入中。作者在不同的空间位置随机抽取几个方形的K×K 个patch。然后,将每个窗口中固定百分比的patch归零。然后,将所有patch从每个窗口按顺序提供给编码器。编码器在自注意层中应用可学习的相对位置编码。作者用一个简单的MLP头将编码器输出的潜在表示转换回其原始特征维,然后用归一化的ground-truth图像计算均方误差。
04
实验
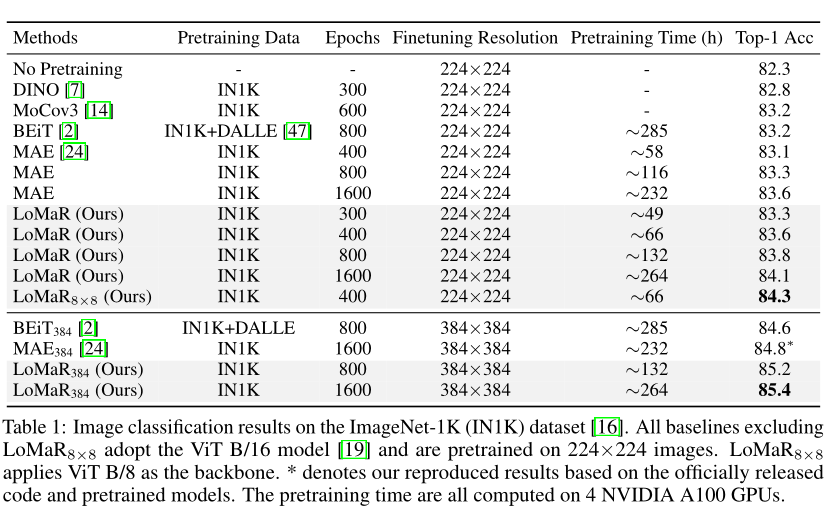
上表总结:了不同自监督学习方法的结果。所有模型在ImageNet-1K上以224×224分辨率进行预训练,并在标记的ImageNet-1K上进行微调。LoMaR在经过400个epoch的预训练后,取得了最好的MAE成绩,为83.6%。经过1600个epoch的预训练后,其性能进一步提高到84.1%。当在384×384分辨率下进行微调时,LoMaR的精度达到85.4%,比最佳baseline高0.6%。总的来说,LoMaR在预训练时间较少的情况下表现优于强baseline。
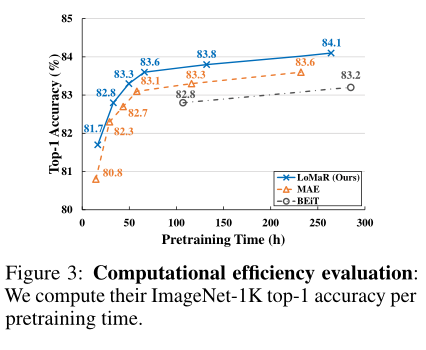
上图显示了LoMaR、MAE和BEiT之间计算效率的比较。作者仔细调整了所有模型,以在GPU和CPU之间实现最佳负载平衡,并在训练期间实现最大图像吞吐量。可以观察到,与baseline相比,LoMaR在较少的预训练时间内始终达到相同或更高的精确度。
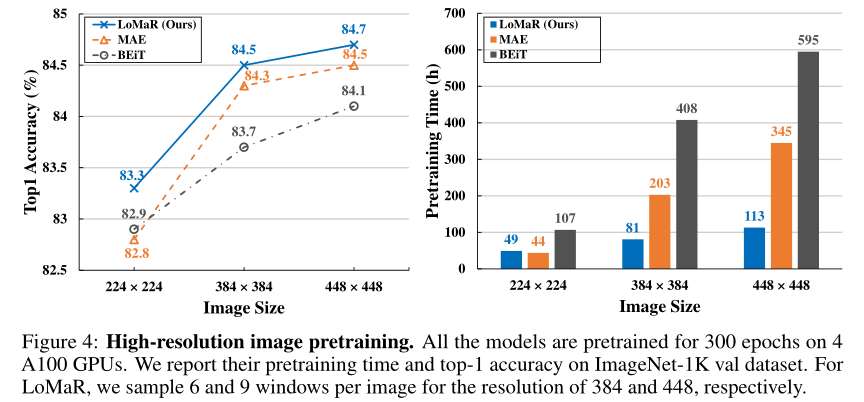
为了评估高分辨率图像上自监督学习行为的效率,作者在ImageNet-1K数据集上对384和448图像大小的LoMaR、MAE和BEiT进行预训练。上图显示了它们的预训练效率和准确性。对于MAE,作者在预训练期间遵循其默认设置;采样75%的patch作为mask。对于LoMaR,作者将分辨率为384和448的视图数设置为6和9,以覆盖每个图像中更多可见的patch。对所有的模型进行预训练300个epoch,并在相同的图像分辨率下对其进行微调。
结果表明,LoMaR在较少的预训练时间内始终优于其他模型,它与窗口数成线性比例。相反,随着分辨率的增加,MAE和BEiT的预训练时间呈二次曲线变化。结果表明,在384×384图像上,LoMaR比MAE(精度+0.2%)快2.5倍,比BEiT(精度+0.8%)快5.0倍,在448×448分辨率下,LoMaR比MAE(精度+0.2%)快3.1倍,比BEiT(精度+0.6%)快5.3倍。

作者在MS COCO上对模型进行了端到端的微调,以完成目标检测和实例分割任务。在ViTDet和ViTAE框架中,作者用预训练的LoMaR模型替换ViT主干。从上表中可以看出,LoMaR在COCO目标检测和实例分割基准上有持续的性能改进。
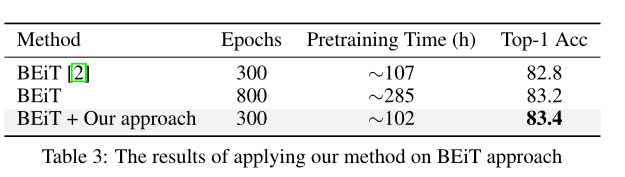
本文的核心思想,局部掩蔽重建,可以很容易地集成到其他生成性自监督学习方法中。为了在不同的范式中检验其有效性,作者将其集成到BEiT中。上表中的结果表明,该策略将准确率从82.8%提高到83.4%,高于800个epoch的原始BEiT预训练。
作者创建了具有多种不同窗口大小(如5×5、7×7、9×9、11×11和14×14)的LoMaR(简单编码器+RPE)版本较小的窗口比较大的窗口覆盖的可见patch少得多,这造成了不公平的比较。为了鼓励公平性,作者为每个窗口大小分配不同数量的视图,如上表所示,以便所有条件在训练中都有相似数量的可见patch。

上图中的结果表明,当将窗口大小从14减小到7时,性能保持稳定,但当窗口大小减小到5时,性能急剧下降。另一方面,较大的窗口大小通常会导致较高的计算成本,如上图(右)所示;14×14窗口的预训练时间几乎是7×7窗口的两倍。因此,从效率和精度的角度来看,窗口大小7×7可以被视为局部掩蔽重建的最佳权衡。

作者还探索了局部掩蔽重建场景下的最佳掩蔽比(见上图)。作者在30%到90%的不同掩蔽比上训练以前的最佳设置(简单编码器+窗口大小7×7+RPE)。结果表明,过低(30%)或过高(90%)的掩蔽比都不是最优的,因为它们会使训练任务过于简单或复杂。作者发现,80%的掩蔽比可以获得最佳性能,这与MAE中观察到的60%的掩蔽比可以获得最佳微调性能不同。基于这一动机,作者在实验中采用了80%的掩模比。

作者在上图中定性地显示了预训练模型的重建性能。从ImageNet-1K和MS COCO中随机抽取了几幅图像。然后,在每幅图像中采样一个包含7×7个patch的区域,并在窗口中80%的置为0的patch进行重建。可以看出,LoMaR能够生成合理的图像,这也证实了最初的猜测,即丢失的patch可以仅从局部周围的patch中恢复。

作者在上图中显示了不同掩蔽率下的重建性能。对于每幅图像,采样一个窗口,并随机掩蔽60%、70%、80%和90%的patch进行重建。作者发现LoMaR可以在不同的掩蔽尺度下合理地恢复损坏的图像;即使只有5个可见patch作为线索(90%掩蔽率),它仍然可以成功地重建图像。这表明LoMaR已经学习了高容量模型,可以推断出复杂的重建。
05
总结:
自监督学习(SSL)可以从大量未标记数据的训练中获益。然而,在大规模的预训练下,它们的高计算要求仍然是一个值得关注的问题。在本文的研究中,作者观察到用于生成SSL的局部掩蔽重建(LoMaR)比MAE和BEiT等有影响力的著作使用的全局版本更有效。
LoMaR在图像分类、实例分割和目标检测方面具有良好的泛化能力;它可以很容易地合并到MAE和BEiT中。LoMaR有希望将SSL扩展到更大的数据集和更高的分辨率,以及计算更密集的数据集,如视频。LoMaR的另一个优点在于,当图像patch数量增加时,效率会提高。
主要原因是LoMaR限制了局部窗口内的自注意,其计算复杂度随每幅图像的采样窗口数呈线性增长。此特性可以在高图像分辨率下进行有效的预训练,而对于其他SSL方法来说,这将非常昂贵。它可以使许多视觉任务受益,例如需要在像素级进行密集预测的对象检测或实例分割。尽管LoMaR相对于其他高分辨率图像基线的预训练效率增益很高,但与MAE相比,LoMaR相对于低分辨率图像的效率提高有限。
更多相关内容
-
深度学习论文精读[GAN]:利用深度生成先验进行多用途图像修复与处理
笔者最近在集中时间学习 对抗生成网络(GAN) ,特别是深度生成先验进行多用途图像修复与处理,...
-
卧槽,卷王之王呀!又一个论文神器
笔者最近在集中时间学习 对抗生成网络(GAN) ,特别是深度生成先验进行多用途图像修复与处理,...
-
深度学习论文精读[GAN]:利用深度生成先验进行多用途图像修复与处理
笔者最近在集中时间学习 对抗生成网络(GAN) ,特别是深度生成先验进行多用途图像修复与处理,...
-
2022 Oral火了!2D图像秒变逼真3D物体!虚拟爵士乐队来了!
你见过乐器自己演奏么?看看这个: 图1. "活灵活现"的虚拟乐器还是在 NVIDIA 服务器房间里面"尽情"般...






推荐阅读








