
产业新知热门
 加国央行再次疯狂加息 月供将暴涨 物价竟会这样变化
加国央行再次疯狂加息 月供将暴涨 物价竟会这样变化
 无人幸免的购物节“大逃杀”
无人幸免的购物节“大逃杀”
 兼职做自媒体这些天:有人年入五块四,有人时薪一百二
兼职做自媒体这些天:有人年入五块四,有人时薪一百二
 瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
 武汉大学疑似出现霍乱病例
武汉大学疑似出现霍乱病例
 期货不严格止损是超短线交易失败的根源
期货不严格止损是超短线交易失败的根源
 ,精细赛道也能走到上市!
,精细赛道也能走到上市!
 预制菜,会有“刺客”吗
预制菜,会有“刺客”吗

推荐资讯
让区块链变成人人可用的工具,上海原创Web3.0操作系统是如何诞生的
隐私之变|自我主张时代变革,从构建WEB3.0的ID体系开始
被投资圈盯上,风头超过元宇宙,Web3.0到底是啥?
Web3.0,勾勒下一代互联网模样
为什么说中国汽车产业已经真正“支棱”起来了
我在新能源汽车行业打工10年:从月薪2千涨至年薪40万,终于熬出头
对话梅宏院士:数字化转型不是想不想,而是必须转
王兴继续“电商零售梦”:告别社区团购 美团优选变身明日达超市

MarkBERT:巧妙地将词的边界标记信息融入模型
 财经快报
|
2022/08/30 12:28:50
财经快报
|
2022/08/30 12:28:50
一句话概述:在 Token 中加入你感兴趣的词的边界标记。
MarkBERT 不是基于词的 BERT,依然是基于字,但巧妙地将 「词的边界标记」 信息融入模型。这样可以统一处理任意词,无论是不是 OOV。另外,MarkBERT 还有两个额外的好处:
-
首先,在边界标记上添加单词级别的学习目标很方便,这是对传统字符和句子级预训练任务的补充;
-
其次,可以通过用 POS 标签特定的标记替换通用标记来轻松合并更丰富的语义。
在 NER 任务上取得了 2 个点的提升,在文本分类、关键词识别、语义相似任务上也取得了更好的精度。
这个简单但有效的中文预训练模型 MarkBERT,考虑了词信息但没有 OOV 问题。具体有以下优势:
-
统一的方式处理常用词和低频词,没有 OOV 问题。
-
Marker 的引入允许设计词级别的预训练任务,这是对字级别的 MLM 和句子级别的 NSP 的补充。
-
容易扩展加入更多单词语义(词性、词法等)。
预训练阶段有两个任务:
-
MLM:对 Marker 也进行了 MASK,以便模型能学习到边界知识。
-
替换词检测:人工替换一个词,然后让模型分辨标记前面的词是不是正确的。
MarkBERT预训练 : MarkBERT
如下图所示:
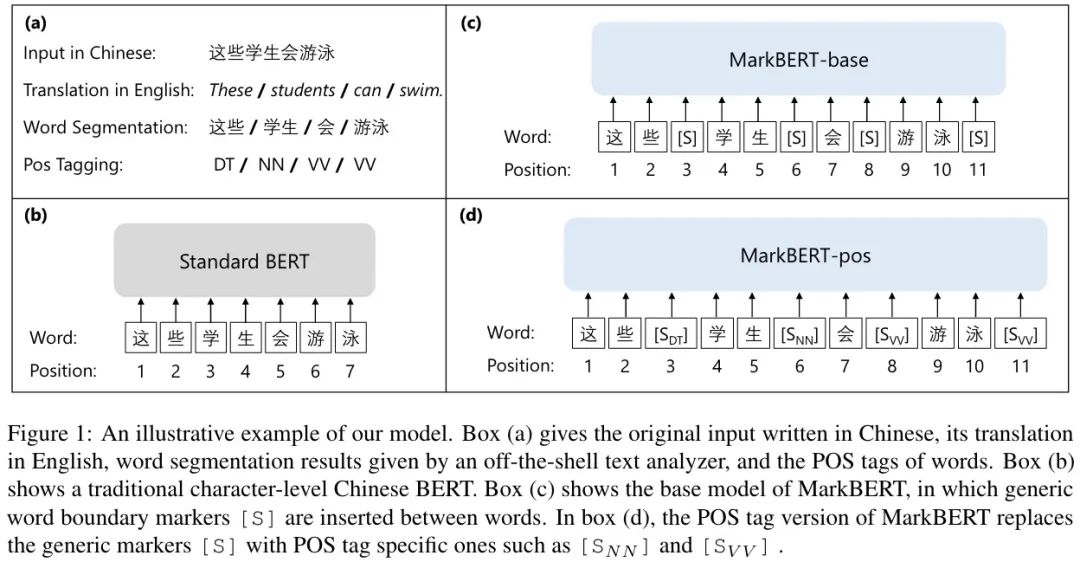
首先分词,在词中间插入特殊标记,这些标记也会被当做普通的字符处理。有位置,也会被 MASK,这样编码时就需要注意词的边界,而不是简单地填充,MASK 预测任务变得更有挑战(预测需要更好地理解单词边界)。这样,模型依然是字符级别的,但它知道了单词的边界(因为单词的信息是显式给出的)。
替换词检测
具体而言,当一个词被替换成混淆词,标记应该做出「被替换」的预测,标签为 False,否则为 True。
该损失函数会和 MLM 的损失函数加在一起作为多任务训练过程。混淆词来自同义词或读音相似的词,通过这个任务,标记可以对上下文中的单词跨度更敏感。使用 POS 做标记的模型称为 MarkBERT-POS。
预训练
MASK 的比例依然是 15%,30% 的时间不插入任何标记(原始的 BERT);50% 的时间执行 WWM 预测任务;其余时间执行 MLM 预测任务。
在插入标记中,30% 的时间将词替换为基于读音的混淆词或基于同义词的混淆词,标记预测读音混淆标记或同义词混淆标记;其他时间标记预测正常单词标记。为了避免不平衡标签,只计算正常标记上 15% 的损失。
实验 :
在 NER 任务上的效果如下表所示:
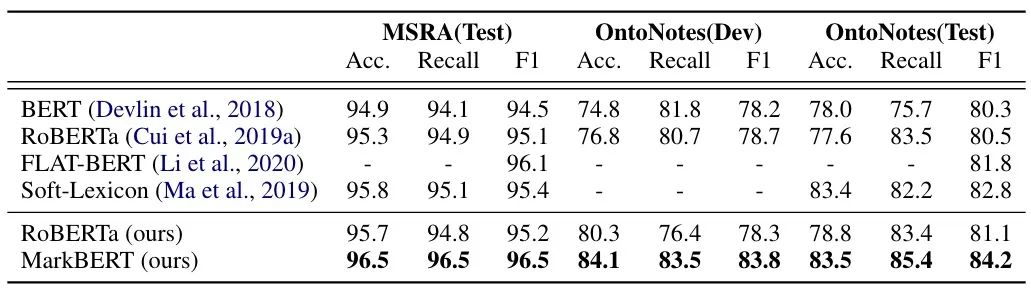
可以看到,效果提升还是很明显的。
在三个任务上做了消融实验:
-
MarkBERT-MLM:只有 MLM 任务
-
MarkBERT-rwd:在替换词检测时,分别移除近音词或同义词
-
MarkBERT-w/o:在下游任务微调时去掉 Marker(和原始 BERT 一样用法)
结果如下表所示:
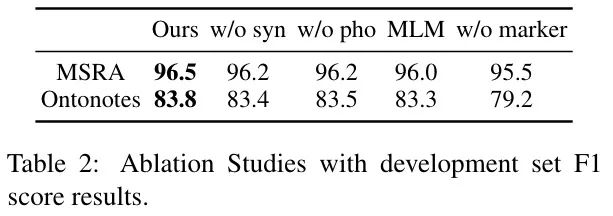
结论如下:
-
MarkBERT-MLM 在 NER 任务中获得显著提升,说明单词边界信息在细粒度任务中很重要。
-
不插入标记,MarkBERT-w/o 也达到了和 baseline 相近的效果,说明 MarkBERT 可以像 BERT 一样使用。
-
对 NER 任务来说,插入标记依然重要,表明 MarkBERT 结构在学习需要这种细粒度表示的任务的单词边界方面是有效的。
讨论 :
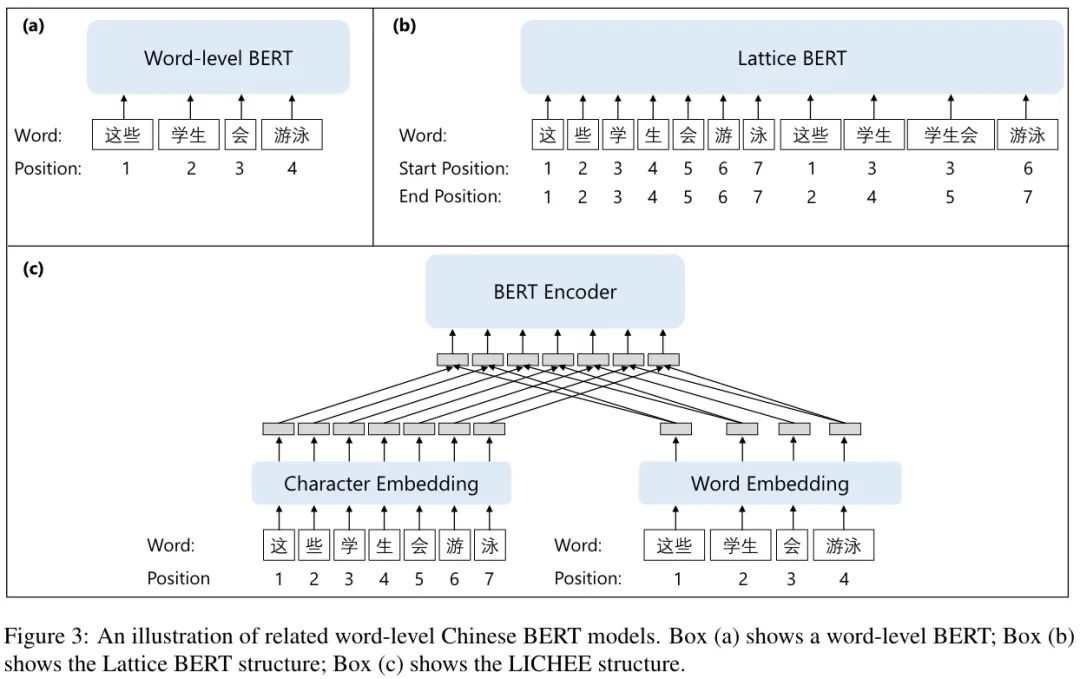
已有的中文 BERT 融入词信息有两个方面的策略:
-
在预训练阶段使用词信息,但在下游任务上使用字符序列,如 Chinese-BERT-WWM,Lattice-BERT。
-
在下游任务中使用预训练模型时使用单词信息,如 WoBERT,AmBERT,Lichee。
另外在与实体相关的 NLU 任务,特别是关系分类中有探讨插入标记的想法。给定一个主语实体和宾语实体,现有工作注入非类型标记或实体特定标记,并对实体之间的关系做出更好的预测。
这篇论文当时刷到时觉得真心不错,方法很简单但很巧妙,一下子解决了中文预训练模型「词」的处理,非常方便地就可以引入词级别的任务,以及丰富的词语义。其实,我们甚至可以只针对「部分感兴趣的词」添加标记,剩下的依然按字处理。






推荐阅读








