
产业新知热门
 加国央行再次疯狂加息 月供将暴涨 物价竟会这样变化
加国央行再次疯狂加息 月供将暴涨 物价竟会这样变化
 无人幸免的购物节“大逃杀”
无人幸免的购物节“大逃杀”
 兼职做自媒体这些天:有人年入五块四,有人时薪一百二
兼职做自媒体这些天:有人年入五块四,有人时薪一百二
 瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
 武汉大学疑似出现霍乱病例
武汉大学疑似出现霍乱病例
 期货不严格止损是超短线交易失败的根源
期货不严格止损是超短线交易失败的根源
 ,精细赛道也能走到上市!
,精细赛道也能走到上市!
 预制菜,会有“刺客”吗
预制菜,会有“刺客”吗

推荐资讯
让区块链变成人人可用的工具,上海原创Web3.0操作系统是如何诞生的
隐私之变|自我主张时代变革,从构建WEB3.0的ID体系开始
被投资圈盯上,风头超过元宇宙,Web3.0到底是啥?
Web3.0,勾勒下一代互联网模样
为什么说中国汽车产业已经真正“支棱”起来了
我在新能源汽车行业打工10年:从月薪2千涨至年薪40万,终于熬出头
对话梅宏院士:数字化转型不是想不想,而是必须转
王兴继续“电商零售梦”:告别社区团购 美团优选变身明日达超市

一个简单但是能上分的特征标准化方法
 财经快报
|
2022/08/30 12:42:48
财经快报
|
2022/08/30 12:42:48
来源:DeepHub IMBA
本文介绍的方法叫Robust Scaling,正如它的名字一样能够获得更健壮的特征缩放结果。
一般情况下我们在做数据预处理时都是使用StandardScaler来特征的标准化,如果你的数据中包含异常值,那么效果可能不好。
这里介绍的方法叫Robust Scaling,正如它的名字一样能够获得更健壮的特征缩放结果。与StandardScaler缩放不同,异常值根本不包括在Robust Scaling计算中。因此在包含异常值的数据集中,更有可能缩放到更接近正态分布。
StandardScaler会确保每个特征的平均值为0,方差为1。而RobustScaler使用中位数和四分位数(四分之一),确保每个特征的统计属性都位于同一范围。
公式如下:
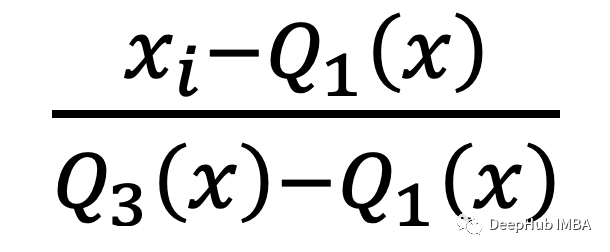
我们使用一些数据看看他的结果,首先创建测试数据
import numpy as np
import matplotlib.pyplot as plt
nb_samples = 200
mu = [1.0, 1.0]
covm = [[2.0, 0.0], [0.0, 0.8]]
X = np.random.multivariate_normal(mean=mu, cov=covm, size=nb_samples)
然后使用三个常用的缩放方法对数据进行预处理:
from sklearn.preprocessing import StandardScaler, RobustScaler, MinMaxScaler
ss = StandardScaler()
X_ss = ss.fit_transform(X)
rs = RobustScaler(quantile_range=(10, 90))
X_rs = rs.fit_transform(X)
mms = MinMaxScaler(feature_range=(-1, 1))
X_mms = mms.fit_transform(X)
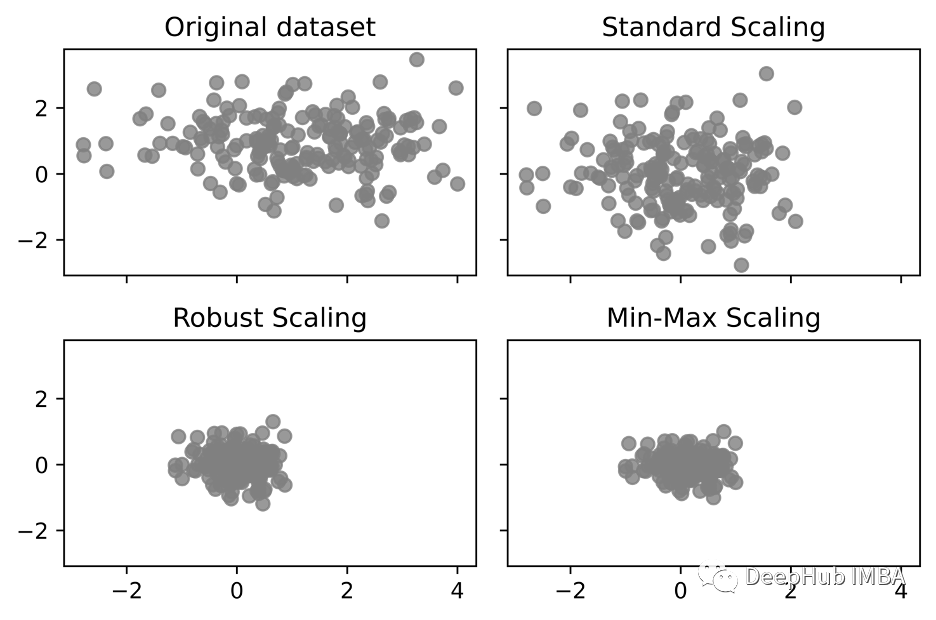
可视化:
fig, ax = plt.subplots(2,2, sharex=True, sharey=True, dpi=1000)
ax[0][0].scatter(X[:,0], X[:,1], c='gray', alpha = .8)
ax[0][1].scatter(X_ss[:,0], X_ss[:,1], c='gray', alpha = .8)
ax[1][0].scatter(X_rs[:,0], X_rs[:,1], c='gray', alpha = .8)
ax[1][1].scatter(X_mms[:,0], X_mms[:,1], c='gray', alpha = .8)
ax[0][0].set_title('Original dataset')
ax[0][1].set_title('Standard Scaling')
ax[1][0].set_title('Robust Scaling')
ax[1][1].set_title('Min-Max Scaling')
plt.tight_layout()
为什么这个方法不会受异常值的影响?
如果数据中存在很大的异常值,可能会影响特征的平均值和方差进而影响标准化结果。而RobustScaler使用中位数和四分位数间距进行缩放,这样可以缩小异常值的影响。
最后我们再看一下这个方法的参数。
quantile_range : tuple (q_min, q_max), 0.0 < q_min < q_max < 100.0, default=(25.0, 75.0)
quantile_range用于计算scale_的分位数范围。默认情况下,它等于IQR,即q_min是第一个分位数,q_max是第三个分位数,也就是我们上面公式中的Q1和Q3。
编辑:于腾凯
更多相关内容
-
比特币底部特征已现,24个月内将再创新高,但矿工、Hodlers抛压巨大,短期仍有阵痛
读懂趋势,预见未来。大家好,我是老白。 截止到今天,比特币已连跌5个交易日,再次逼近19000,链上数据...
-
服装终端店铺的品类规划
服饰品牌公司该如何进行终端的品类规划?商品该如何组合才能满足消费者的最佳购物体验?。 一、终...
-
2022年中国新式健身房行业研究报告(附下载)
需要下载本报告的朋友,可以扫描下方二维码进圈,1万+份报告,2000+会员,高清原版,无限制下载 (...
-
三板斧+必杀技,瑞数信息助力构建安全可信的数字世界
近日,以“安全生长,重启一夏”为主题的“CIS大会 夏日版·Summer live”正式开启。二十余位资深网安专...
-
| 深入研究不平衡回归问题
本文大体梳理一下数据不平衡这个问题在分类以及回归上的一部分研究现状。 来给大家介绍一下我们的...
-
华为诺亚实验室 | 围绕计算成像、极简计算、图文生成、3D全感知、OOD泛化、无损压缩等
CVPR(Computer Vision and Pattern Recognition)由IEEE主办,是计算机视觉领域的三大顶会(CVPR、I...
-
系列篇丨一文读懂流量承接,轻松实现百万销量
随着平台流量质量的不断下降,不少活动方发现,虽然外部渠道投放后,活动的流量大规模增长,但最终留存...
-
用于复杂微器件制造
前言 一体化机器人 用于复杂微器件制造 7月11日下午,中国(绵阳)科技城工业技术研究院对外发布了由...
-
Bio.完成2500万美元A轮融资,前百时美施贵宝公司肿瘤研究专家加入公司
“ 资金将用于扩展mRNA 2.0平台,推进免疫肿瘤候选药物KR-335的申请。 ”作者:Rita 编辑:






推荐阅读








