
产业新知热门
 加国央行再次疯狂加息 月供将暴涨 物价竟会这样变化
加国央行再次疯狂加息 月供将暴涨 物价竟会这样变化
 无人幸免的购物节“大逃杀”
无人幸免的购物节“大逃杀”
 兼职做自媒体这些天:有人年入五块四,有人时薪一百二
兼职做自媒体这些天:有人年入五块四,有人时薪一百二
 瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
瞄准数亿过敏人群,以过敏数字疗法为切点,杭州数智医掘金新蓝海
 武汉大学疑似出现霍乱病例
武汉大学疑似出现霍乱病例
 期货不严格止损是超短线交易失败的根源
期货不严格止损是超短线交易失败的根源
 ,精细赛道也能走到上市!
,精细赛道也能走到上市!
 预制菜,会有“刺客”吗
预制菜,会有“刺客”吗

推荐资讯
让区块链变成人人可用的工具,上海原创Web3.0操作系统是如何诞生的
隐私之变|自我主张时代变革,从构建WEB3.0的ID体系开始
被投资圈盯上,风头超过元宇宙,Web3.0到底是啥?
Web3.0,勾勒下一代互联网模样
为什么说中国汽车产业已经真正“支棱”起来了
我在新能源汽车行业打工10年:从月薪2千涨至年薪40万,终于熬出头
对话梅宏院士:数字化转型不是想不想,而是必须转
王兴继续“电商零售梦”:告别社区团购 美团优选变身明日达超市

不到1ms在iPhone12上完成推理,苹果提出移动端高效主干网络MobileOne
 财经快报
|
2022/08/19 11:57:31
财经快报
|
2022/08/19 11:57:31
【导读】 来自苹果的研究团队分析了现有高效神经网络的架构和优化瓶颈,提出了一种新型移动端主干网络。
用于移动设备的高效神经网络主干通常针对 FLOP 或参数计数等指标进行优化。但当部署在移动设备上,这些指标与网络的延迟可能并没有很好的相关性。
基于此,来自苹果的研究者 通过在移动设备上部署多个移动友好网络对不同指标进行广泛分析,探究了现有高效神经网络的架构和优化瓶颈 ,提供了缓解这些瓶颈的方法。该研究设计了一个高效的主干架构 MobileOne,它的变体在 iPhone12 上的推理时间少于 1 ms,在 ImageNet 上的 top-1 准确率为 75.9%。

论文地址:https://arxiv.org/abs/2206.04040
MobileOne 架构不仅实现了 SOTA 的性能,还在移动设备上提速了许多倍。其中,最好的模型变体在 ImageNet 上获得了与 MobileFormer 相当的性能,同时速度提高了 38 倍。MobileOne 在 ImageNet 上的 top-1 准确率比 EfficientNet 在相似的延迟下高 2.3%。
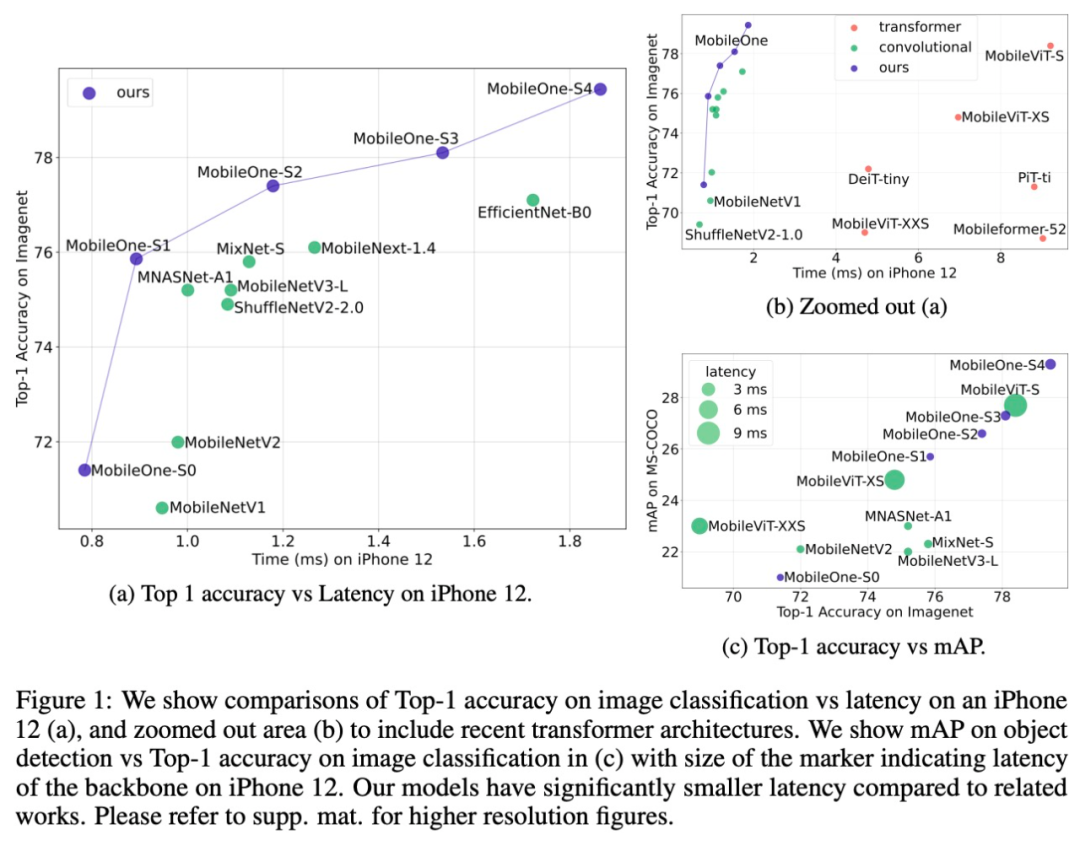
此外,该研究还表明 MobileOne 可以推广到多个任务 —— 图像分类、目标检测和语义分割,与部署在移动设备上的现有高效架构相比,准确度显著提高,延迟显著缩短。
ntent="t"> 方法概览
研究者首先分析了常用指标(FLOP 和参数计数)与移动设备延迟的相关性,并分析了架构中不同设计选择对手机延迟的影响。
指标相关性
比较两个或多个模型大小最常用的成本指标是参数计数和 FLOPs。但是,它们可能与实际移动应用程序中的延迟没有很好的相关性,该研究对此进行了深入的分析,对高效神经网络进行了基准测试。
该研究并使用近期模型的 Pytorch 实现将它们转换为 onNX 格式。该研究使用 Core ML Tools 将每个模型转换成 coreml 包,然后开发了一个 iOS 应用程序来测量 iPhone12 上的模型延迟。
如下图 2 所示,该研究绘制了延迟与 FLOPs 和延迟与参数计数的关系图。研究者观察发现许多具有较高参数计数的模型延迟较低。在类似的 FLOPs 和参数计数下,MobileNets 等卷积模型对于比相应的 Transformer 模型延迟更低。
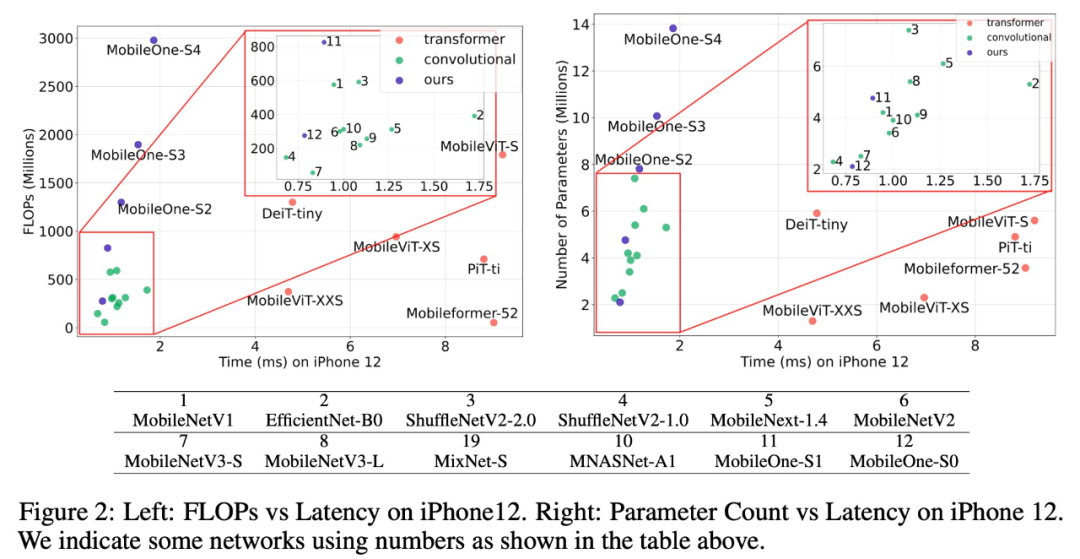
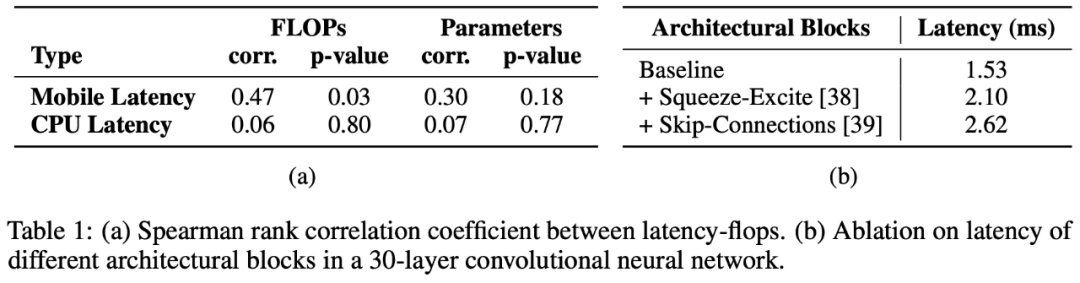
研究者还估计了下表 1 (a) 中的 Spearman 排名相关性,并发现延迟与 FLOPs 适度相关,而与移动设备上高效架构的参数计数弱相关,在台式机 CPU 上相关性会更低。
激活函数的关键瓶颈
为了分析激活函数对延迟的影响,该研究构建了一个 30 层的卷积神经网络,并在 iPhone12 上使用不同的激活函数对其进行基准测试,这些激活函数通常被用于高效的 CNN 主干网络。下表 3 中的所有模型除了激活函数之外,架构都是相同的,但它们的延迟却截然不同。
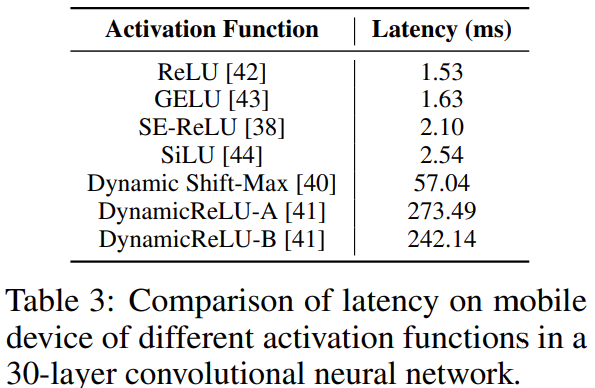
这种差异主要是由最近提出的激活函数(例如 SE-ReLU、Dynamic Shift-Max 和 DynamicReLUs)造成的。 MobileOne 中仅使用 ReLU 激活函数。架构块影响运行时性能的两个关键因素是内存访问成本和并行度。
在多分支架构中,内存访问成本显著增加,因为必须存储来自每个分支的激活函数来计算图中的下一个张量。如果网络的分支数较少,则可以避免此类内存瓶颈。强制同步的架构块(如 Squeeze-Excite 块中使用的全局池化操作)也会因同步成本而影响整体运行时间。为了演示内存访问成本和同步成本等隐藏成本,该研究在 30 层卷积神经网络中大量使用残差连接(skip connection)和 Squeeze-Excite 块,表 1b 展示了它们对延迟的影响。
基于此,该研究采用了在推理时没有分支的架构,从而降低了内存访问成本,并在 MobileOne 的最大变体中使用 Squeeze-Excite 块以提高准确性。最终,MobileOne 架构如下图所示。
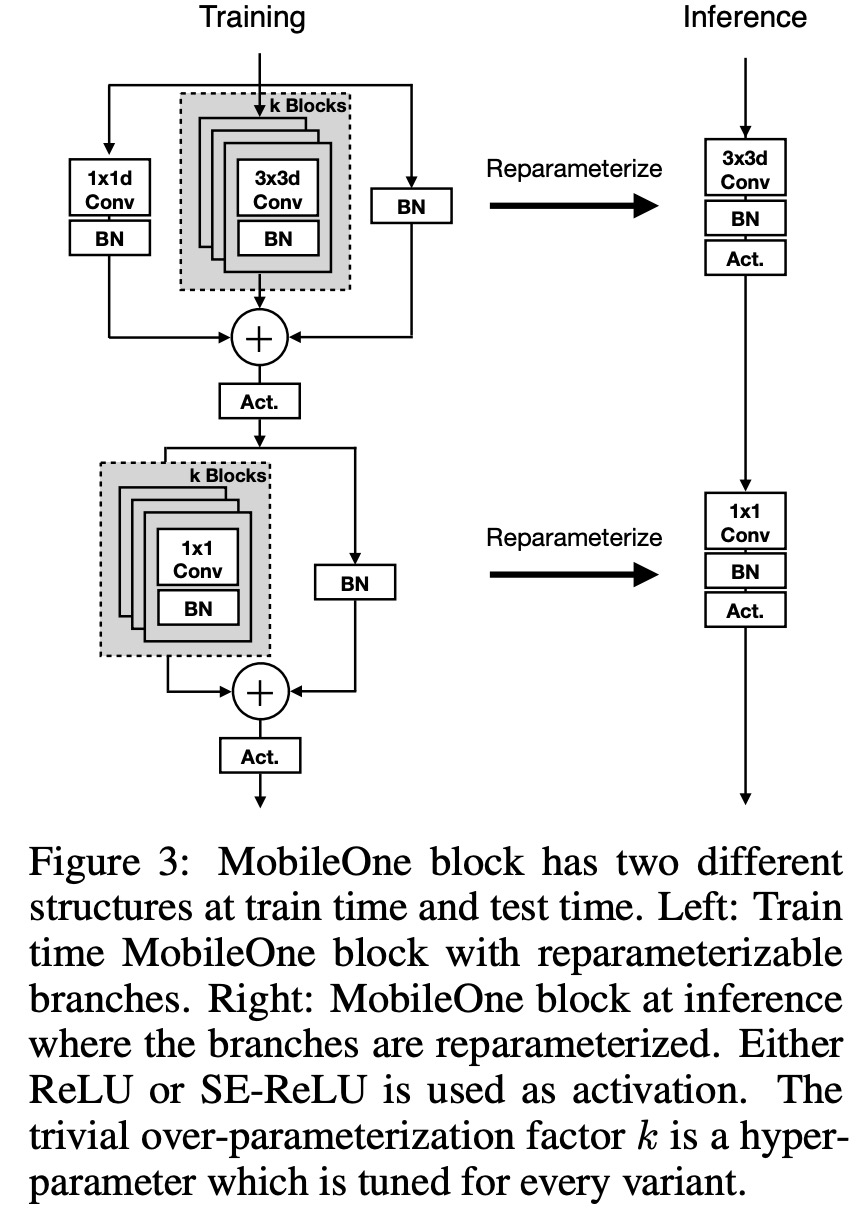
为了提高性能,模型在以下几个方面进行了扩展:宽度、深度和分辨率。该研究没有随着 FLOP 和内存消耗的增加而扩大输入分辨率,这对移动设备上的运行时性能是有害的。
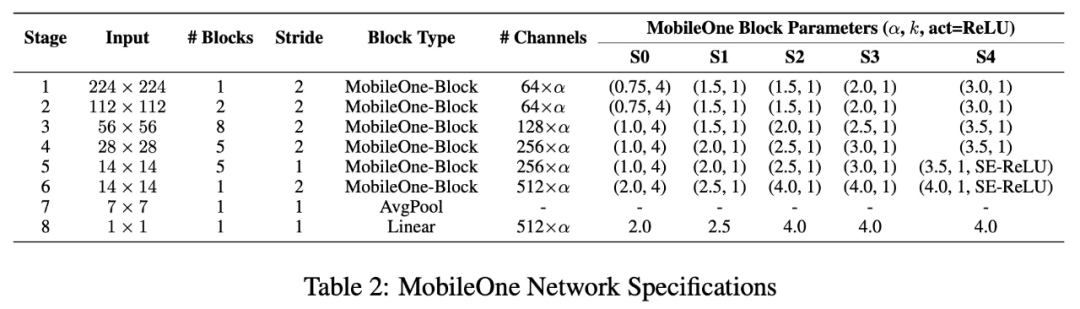
由于新模型在推理时没有多分支架构,因此它不会产生数据移动成本。与多分支架构(如 MobileNet-V2、EfficientNets 等)相比,苹果的新模型能够积极地扩展模型参数,而不会产生很高的延迟成本。
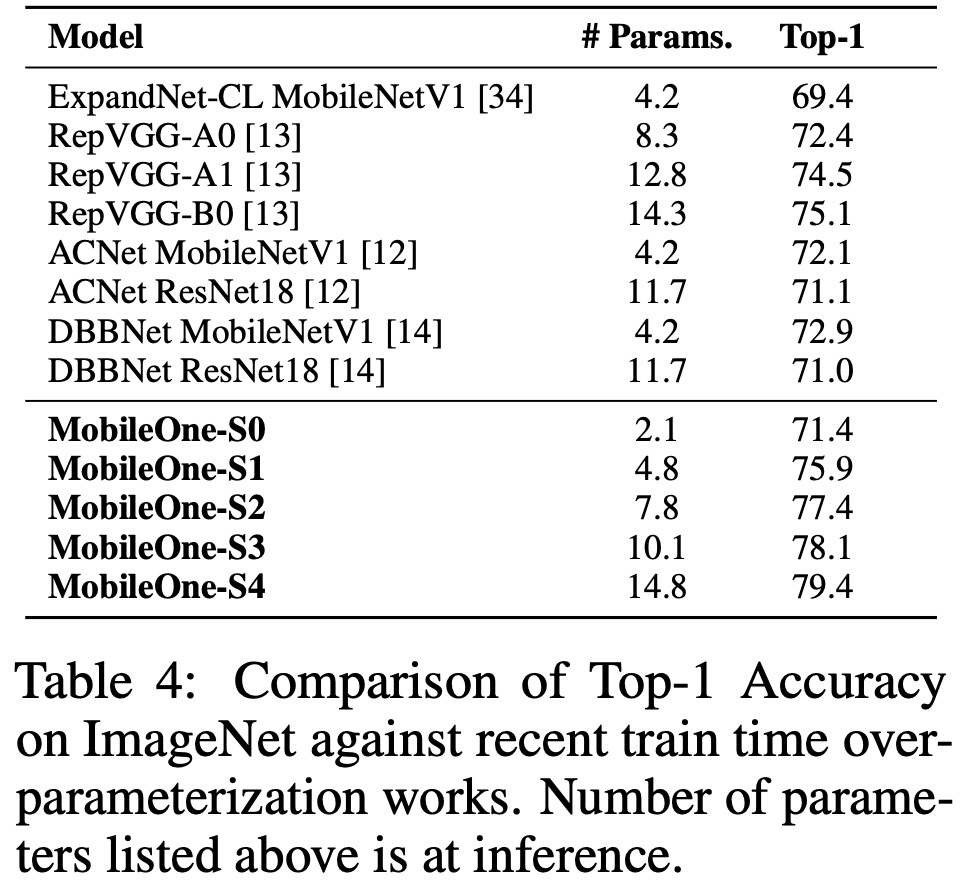
增加参数数量能够让该模型很好地泛化到其他计算机视觉任务上,如目标检测和语义分割。表 4 将新模型与最近的训练时间过参数化工作进行了比较,结果表明 MobileOne-S1 变体的性能优于 RepVGG-B0,约比后者高 3 倍。
ntent="t"> 实验及结果
在移动设备上获得准确的延迟测量可能很困难。在 iPhone 12 上,没有命令行访问或功能来保留所有计算结构以仅用于模型执行。同时也无法将往返延迟分解为网络初始化、数据移动和网络执行等类别。为了测量延迟,该研究使用 swift 开发了一个 iOS 应用程序对这些模型进行基准测试。该应用程序使用 Core ML 运行模型。
在基准测试期间,应用程序会多次运行模型(默认为 1000 次)并累积统计信息。为了实现最低延迟和最高一致性,手机上的所有其他应用程序都将关闭。
如下表 8 所示,该研究报告了完整的模型往返延迟。其中大部分时间可能不是来自该模型本身的执行进程,但在实际应用程序中,这些延迟是不可避免的。因此,该研究将它们包含在报告的延迟中。为了过滤掉来自其他进程的中断,该研究报告了所有模型的最小延迟。
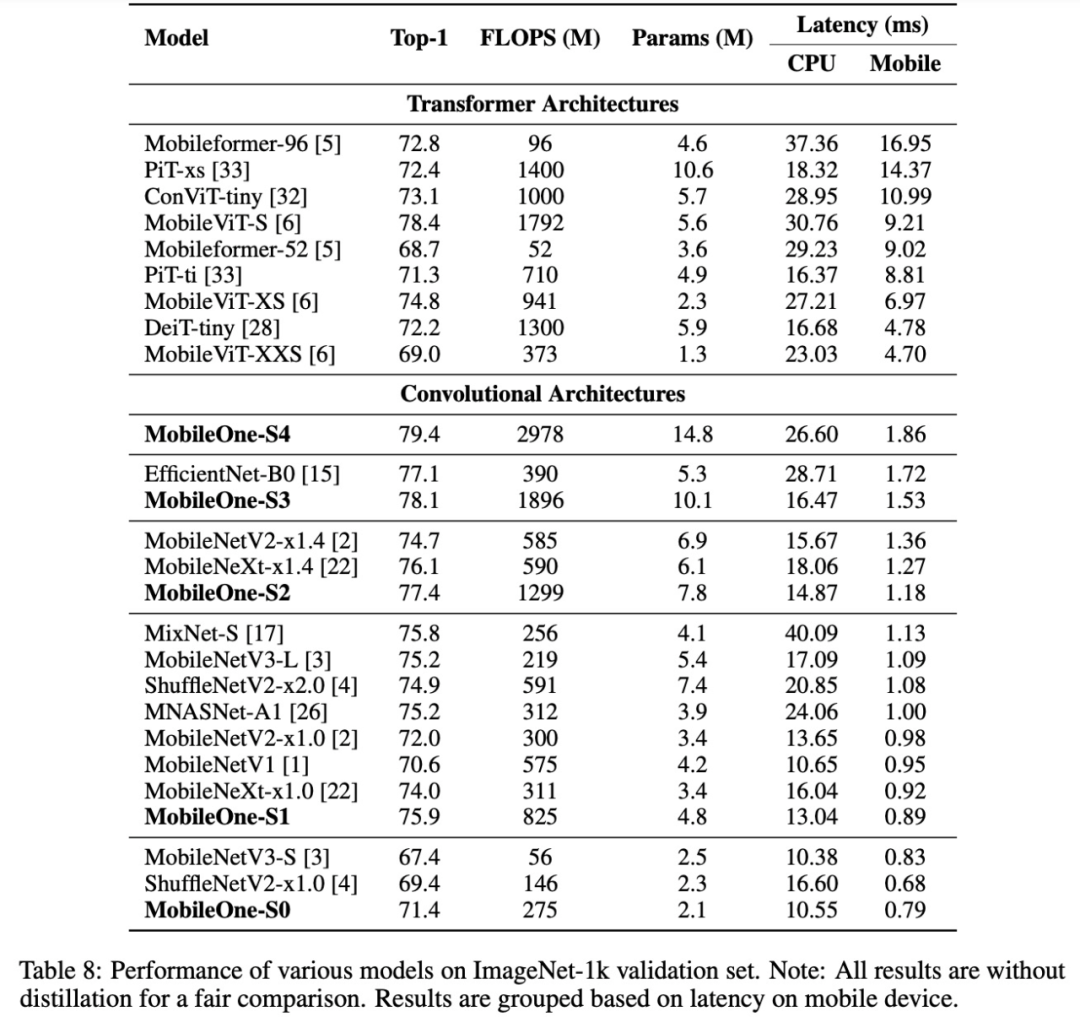
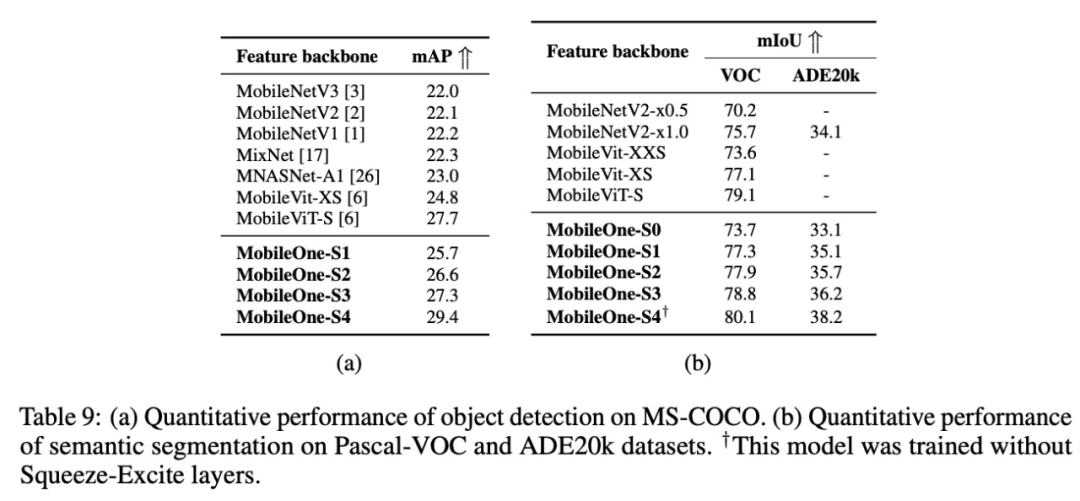
此外,该研究还报告了几种模型在 MS COCO 数据集上的目标检测任务性能和在 Pascal VOC 、ADE 20k 数据集上语义分割任务性能,MobileOne 的性能普遍优于其他模型,具体结果如下表 9 所示。
更多相关内容
-
趣链隐私计算平台全量通过“可信隐私计算评测”
本文作者:趣链科技 7月13日,由中国通信标准化协会指导,中国信息通信研究院、隐私计算联盟主办的“202...
-
李伟:区块链是数字化时代的“安全基座”
本文作者:趣链科技 日前,由国家工业信息安全发展研究中心主办、区块链技术与数据安全工信部重点实验室...
-
中国混动“天花板”极限首测!一箱油行驶1711km
为迎合消费者需求,同时顺应国家“双碳”战略,一众超级混动品牌如雨后春笋般涌现出来,作为国内唯一拥...
-
京东云总裁高礼强:产业数字化的下一站是数智供应链
“产业数字化的下一站,是数智供应链。 ”7月13日,京东集团副总裁、京东云事业群总裁高礼强,在2022京...
-
Esri推出用于设施寻路的室内定位系统
ArcGIS IPS室内定位软件助力提升运营效率和安全性智能手机导航应用已经给人们带来了更大的个人自由度,...
-
自动筛选 精准意向 支持打断 操作简单
智能语音机器人就是代替销售人员自动给客户拨打电话,自动沟通,自动筛选,留下有意向的客户,推送给你...
-
ai智能获客系统,大数据拓客系统,各行业高效获客必备!
大数据智能营销拓客系统,认证正版--鹰眼智客远程演示,同威:15538360637智能拓客系统,现在市面上的一...
-
高效做营销 就选鹰眼智客!
鹰眼智客营销系统是一款包含:客户资源采集、微信营销、短信营销、霸屏闪信营销、邮件营销、QQ社群营销...
-
【深圳东莞七夕线上互选】足不出户,在家就能找对象!小红兔微相亲第41期,成功率超高,最高效的线上cp活动
小红兔微相亲 七夕 互选专场 效果好 成
-
快MAE3.1倍、BEiT5.3倍!基于局部mask重建的高效自监督视觉预训练方法LoMaR,同时提高训练精度和效率!
本篇分享论文『Efficient Self-supervised Vision






推荐阅读








